锁专题(三)工作5年了,竟然不知道 volatile 关键字( 三 )
- java
instance = new Singleton();//instance是volatile变量对应汇编0x01a3de1d: movb $0x0,0x1104800(%esi);0x01a3de24: lock addl $0x0,(%esp);有 volatile 变量修饰的共享变量进行写操作的时候会多第二行汇编代码 ,通过查 IA-32 架构软件开发者手册可知 , lock 前缀的指令在多核处理器下会引发了两件事情 。- 将当前处理器缓存行的数据会写回到系统内存 。
- 这个写回内存的操作会引起在其他 CPU 里缓存了该内存地址的数据无效 。
如果对声明了 volatile 变量进行写操作 , JVM就会向处理器发送一条Lock前缀的指令 , 将这个变量所在缓存行的数据写回到系统内存 。
但是就算写回到内存 , 如果其他处理器缓存的值还是旧的 , 再执行计算操作就会有问题 。
所以在多处理器下 , 为了保证各个处理器的缓存是一致的 , 就会实现缓存一致性协议 , 每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了 ,当处理器发现自己缓存行对应的内存地址被修改 , 就会将当前处理器的缓存行设置成无效状态 , 当处理器要对这个数据进行修改操作的时候 , 会强制重新从系统内存里把数据读到处理器缓存里 。
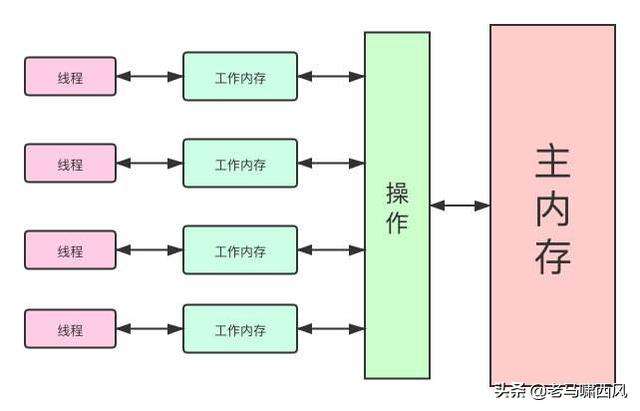 文章插图
文章插图可见性
这两件事情在IA-32软件开发者架构手册的第三册的多处理器管理章节(第八章)中有详细阐述
Lock 前缀指令会引起处理器缓存回写到内存Lock 前缀指令导致在执行指令期间 , 声言处理器的 LOCK# 信号 。
在多处理器环境中 , LOCK# 信号确保在声言该信号期间 , 处理器可以独占使用任何共享内存 。 (因为它会锁住总线 , 导致其他CPU不能访问总线 , 不能访问总线就意味着不能访问系统内存) , 但是在最近的处理器里 , LOCK#信号一般不锁总线 , 而是锁缓存 , 毕竟锁总线开销比较大 。
在8.1.4章节有详细说明锁定操作对处理器缓存的影响 , 对于Intel486和Pentium处理器 , 在锁操作时 , 总是在总线上声言LOCK#信号 。
但在P6和最近的处理器中 , 如果访问的内存区域已经缓存在处理器内部 , 则不会声言LOCK#信号 。
相反地 , 它会锁定这块内存区域的缓存并回写到内存 , 并使用缓存一致性机制来确保修改的原子性 , 此操作被称为“缓存锁定” ,缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据 。
一个处理器的缓存回写到内存会导致其他处理器的缓存无效IA-32处理器和Intel 64处理器使用MESI(修改 , 独占 , 共享 , 无效)控制协议去维护内部缓存和其他处理器缓存的一致性 。
在多核处理器系统中进行操作的时候 , IA-32 和Intel 64处理器能嗅探其他处理器访问系统内存和它们的内部缓存 。
它们使用嗅探技术保证它的内部缓存 , 系统内存和其他处理器的缓存的数据在总线上保持一致 。
例如在Pentium和P6 family处理器中 , 如果通过嗅探一个处理器来检测其他处理器打算写内存地址 , 而这个地址当前处理共享状态 ,那么正在嗅探的处理器将无效它的缓存行 , 在下次访问相同内存地址时 , 强制执行缓存行填充 。
volatile 的使用优化著名的 Java 并发编程大师 Doug lea 在 JDK7 的并发包里新增一个队列集合类 LinkedTransferQueue ,他在使用 volatile 变量时 , 用一种追加字节的方式来优化队列出队和入队的性能 。
追加字节能优化性能?这种方式看起来很神奇 , 但如果深入理解处理器架构就能理解其中的奥秘 。
让我们先来看看 LinkedTransferQueue 这个类 ,它使用一个内部类类型来定义队列的头队列(Head)和尾节点(tail) ,而这个内部类 PaddedAtomicReference 相对于父类 AtomicReference 只做了一件事情 , 就将共享变量追加到 64 字节 。
我们可以来计算下 , 一个对象的引用占4个字节 , 它追加了15个变量共占60个字节 , 再加上父类的Value变量 , 一共64个字节 。
- LinkedTransferQueue.java
/** head of the queue */private transient final PaddedAtomicReference < QNode > head;/** tail of the queue */private transient final PaddedAtomicReference < QNode > tail;static final class PaddedAtomicReference < T > extends AtomicReference < T > {// enough padding for 64bytes with 4byte refsObject p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;PaddedAtomicReference(T r) {super(r);}}public class AtomicReference
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 操盘|中兴统一操盘中兴、努比亚、红魔三大品牌
- 责令|1336款APP被责令整改,三大问题突出
- 三个目标之后|品味莲乡 | 品味
- 苹果|iPhone13迎来变化!或回归指纹解锁,这几点备受用户喜爱
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?