机器学习中的 7 种数据偏差
ITDaily & AI 中国
每日最新 IT 圈 AI 圈新鲜事吐槽 给你想看的 文章插图
文章插图
机器学习中的数据偏差是一种类型的错误 , 其中数据集的某些元素比其他元素的权重更高和/或代表性更强 。 一个有偏见的数据集不能准确地代表模型的用例 , 导致结果偏斜 , 低精度水平和分析错误 。
一般来说 , 机器学习项目的训练数据必须代表真实世界 。 这很重要 , 因为这些数据是机器学习工作的方式 。 数据偏差可能发生在一系列领域 , 从人类报告和选择偏差到算法和解释偏差 。 下图是一个很好的例子 , 说明仅在数据收集和注释阶段就会出现各种偏差 。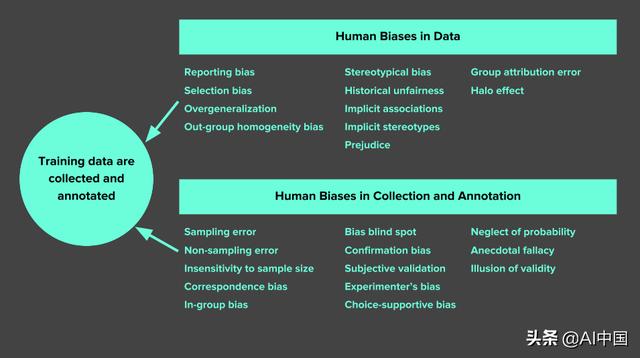 文章插图
文章插图
数据中的人类偏见(摘自Bias in the Vision and Language of AI 。 更多信息和链接在下面) 。 )
解决机器学习项目中的数据偏差意味着首先要确定它在哪里 。 只有在你知道偏见存在于哪里之后 , 你才能采取必要的措施来补救它 , 无论是解决缺乏数据还是改进你的注释流程 。 考虑到这一点 , 对数据的范围、质量和处理保持警惕以尽可能避免偏差是极其重要的 。 这不仅会影响到你的模型的准确性 , 还可以延伸到伦理、公平和包容的问题 。
下面 , 我们列出了机器学习中最常见的七种数据偏差类型 , 以帮助您分析和了解它的发生地点 , 以及您可以做些什么 。
如果你正在寻找机器学习项目的数据采集数据标注的深入信息 , 请务必查看我们的机器学习训练数据深度指南 。
数据偏差的类型虽然不是详尽无遗 , 但这个列表包含了该领域常见的数据偏差的例子 , 以及它发生在哪里的例子 。
- 样本偏差:当一个数据集不能反映模型运行环境的真实情况时 , 就会出现样本偏差 。 这方面的一个例子是某些面部识别系统主要是在白人男子的图像上训练的 。 这些模型对女性和不同种族的人的准确率要低得多 。 这种偏见的另一个名称是选择偏见 。
- 排斥性偏差(Exclusion bias) 排除偏差在数据预处理阶段最为常见 。 最常见的情况是删除被认为不重要的有价值的数据 。 然而 , 它也可能由于系统地排除某些信息而发生 。 例如 , 想象你有一个美国和加拿大的客户销售数据集 。 98%的客户来自美国 , 所以你选择删除位置数据 , 认为它是不相关的 。 然而 , 这意味着你的模型不会发现你的加拿大客户的消费是你的两倍 。
- 测量偏差:当为训练而收集的数据与现实世界中收集的数据不同时 , 或者当错误的测量导致数据失真时 , 就会出现这种类型的偏差 。 这种偏差的一个很好的例子发生在图像识别数据集中 , 其中训练数据是用一种类型的相机收集的 , 但生产数据是用不同的相机收集的 。 在项目的数据标注阶段 , 由于标注不一致 , 也会出现测量偏差 。
- 回忆偏差:这是测量偏差的一种 , 常见于项目的数据标注阶段 。 当你对类似类型的数据进行不一致的标注时 , 就会产生召回偏差 。 这将导致较低的准确性 。 例如 , 假设你有一个团队将手机的图像标记为损坏、部分损坏或未损坏 。 如果有人将一张图片标注为损坏 , 而将一张类似的图片标注为部分损坏 , 那么您的数据将不一致 。
- 观察者偏差:观察者偏差也被称为确认偏差 观察者偏差是指在数据中看到了你期望看到或想看到的东西的效果 当研究人员带着对研究的主观想法进入项目时 , 无论是有意识的还是无意识的 , 都可能发生这种情况 。 当贴标签者让他们的主观想法控制他们的贴标签习惯 , 导致数据不准确时 , 我们也可以看到这种情况 。
- 种族偏见:虽然不是传统意义上的数据偏差 但由于最近在人工智能技术中的普遍性 , 这仍然值得一提 。 当数据偏向于特定的人口统计学时 , 就会出现种族偏见 。 这可以在面部识别和自动语音识别技术中看到 , 它不能像识别白种人那样准确地识别有色人种 。 谷歌的 "包容性图像 "竞赛中就有很好的例子说明这种情况是如何发生的 。
- 联想偏差:当机器学习模型的数据强化和/或增加了文化偏见时 , 就会出现这种偏见 。 你的数据集可能有一个工作的集合 , 其中所有的男性都是医生 , 所有的女性都是护士 。 这并不意味着女性不能当医生 , 男性不能当护士 。 然而 , 就你的机器学习模型而言 , 女医生和男护士是不存在的 。 关联偏见最著名的就是制造性别偏见 , 在挖掘人工智能研究中可见一斑 。
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 跑腿|机器人“小北”上岗 让办事群众少跑腿
- 计算机学科|机器视觉系统是什么
- 机器人|外骨骼康复训练机器人助力下肢运动功能障碍患者康复训练
- 脸上|那个被1亿锦鲤砸中的“信小呆”:失去工作后,脸上已无纯真笑容
- 教学|机器人教学的目标方案
- 体验|VR\/AR体验、3D打印、机器人“对决”……松江这所中学人工智能创新实验室真的赞
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 操作|[LIVE On]黄敏贤和郑多彬充满心碎的下午:机器操作每次都不能通过测试
- 夹缝|“互联网卖菜”背后:夹缝中的菜贩与巨头们的垄断