BERT遇上知识图谱:预训练模型与知识图谱相结合的研究进展( 二 )
此外本文还采用BERT经典的MLM损失函数 , 并使用RoBERTa的原始参数进行初始化;最终本文提出的方法在知识图谱补全和若干NLP任务上均带来了增益 。
4、《CoLAKE: Contextualized Language and Knowledge Embedding》
论文链接:
这篇论文来源于复旦和亚马逊 , 其主要关注于如何使用知识图谱以增强预训练模型的效果 。
本文首先将上下文看作全连接图 , 并根据句子中的实体在KG上抽取子图 , 通过两个图中共现的实体将全连接图和KG子图融合起来;然后本文将该图转化为序列 , 使用Transformer进行预训练 , 并在训练时采用特殊的type embedding来表示实体、词语与其他子图信息 , 如下图所示: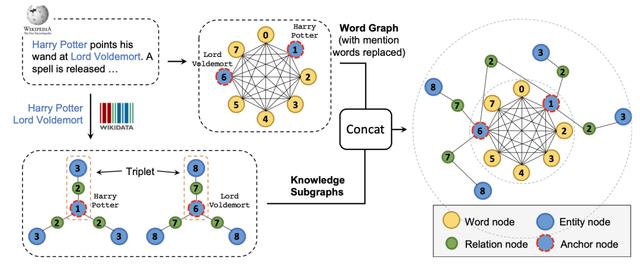 文章插图
文章插图
最终本文将文本上下文和知识上下文一起用MLM进行预训练 , 将mask的范围推广到word、entity和relation;为训练该模型 , 本文采用cpu-gpu混合训练策略结合负采样机制减少训练时间;最终本文提出的方法在知识图谱补全和若干NLP任务上均带来了增益 。
5、《Exploiting Structured Knowledge in Text via Graph-Guided Representation Learning》
论文链接:
这篇论文来源于悉尼科技大学和微软 , 其主要关注于如何使用知识图谱增强预训练模型 。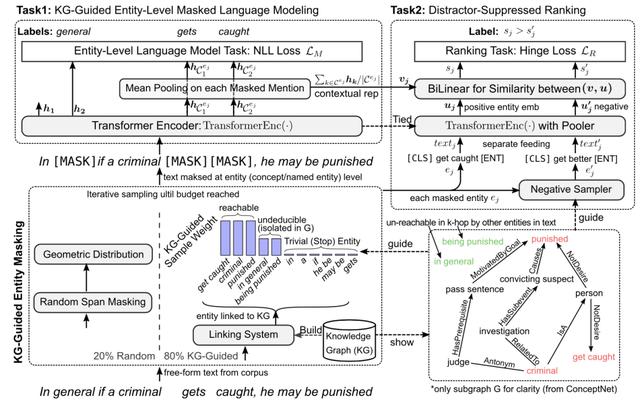 文章插图
文章插图
本文思路比较简洁 , 其提出了一个基于entity的mask机制 , 结合一定的负采样机制来增强模型 。 首先对于输入的每一句话 , 本文首先进行实体链接工作 , 得到其中的entity , 并从知识图谱conceptnet和freebase中召回其邻接的三元组 。
本文利用一个特殊的权重 , 防止在mask时关注于句子中过于简单和过于难的entity , 这样模型在entity-level MLM训练时就关注于较为适合学习的信息;此外本文还引入了基于知识图谱的负采样机制 , 其利用relation来选择高质量的负例 , 以进一步帮助训练;最终本文提出的方法在知识图谱补全和若干NLP任务上均带来了增益 。
6、《K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters》
论文链接:
这篇论文来源于复旦和微软 , 其考虑自适应的让BERT与知识相融合 。
这篇论文考虑如何通过不同的特殊下游任务来帮助向预训练模型融入任务相关的知识 。 首先本文针对不同的预训练任务 , 定义了对应的adapter;在针对具体的下游任务进行fine-tune时 , 可以采用不同的adapter来针对性的加入特征 , 进而增强其效果;如下图所示: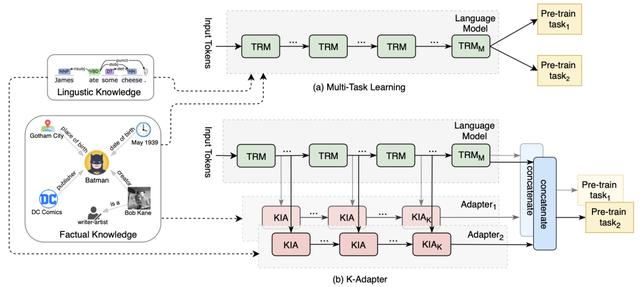 文章插图
文章插图
基于该思想 , 本文提出了两种特殊的adapter , 分别利用factor knowledge和linguistic knowledge 。
针对这两个adapter , 本文提出了针对entity之间的关系分类任务和基于依存关系的分类任务;再fine-tune阶段 , 两个adapter得到的特征可以与BERT或RoBERTa得到的特征一起拼接来进行预测 , 该策略在三个知识驱动数据集上均取得了较大增益 。
7、《Integrating Graph Contextualized Knowledge into Pre-trained Language Models》
论文链接:
这篇论文来自于华为和中科大 , 其主要关注于如何将上下文有关的知识信息加入到预训练模型里 。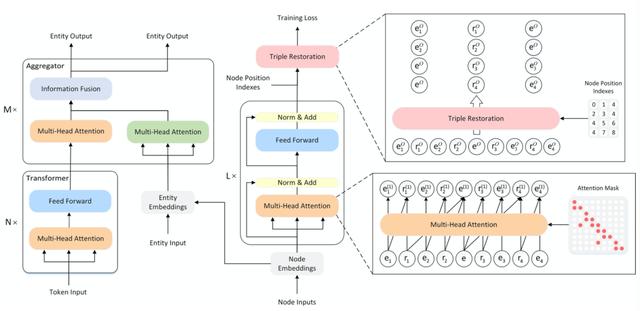 文章插图
文章插图
这篇论文的思想类似于graph-BERT和K-BERT , 其针对给出文本首先检索返回相关的entity三元组 , 再在知识图谱上搜集其相邻的节点以构成子图;
然后将该子图转换成序列的形式 , 输入给传统的Transformer模型(类似graph-BERT) , 通过特殊的mask来约束注意力在相邻节点上(K-BERT);最后用类似于ERNIE的策略将子图中的信息加入到Transformer中;最终该模型在下游的几个医疗相关数据集上取得了增益 。
8、《JAKET: Joint Pre-training of Knowledge Graph and Language Understanding》
论文链接:
这篇论文来自于CMU和微软 , 其主要关注于如何同时对知识图谱和语言模型一起预训练 。
本文使用RoBERTa作为语言模型对文本进行编码 , 增加了relation信息的graph attention模型来对知识图谱进行编码;由于文本和知识图谱的交集在于其中共有的若干entity , 本文采用一种交替训练的方式来帮助融合两部分的知识 , 如下图所示: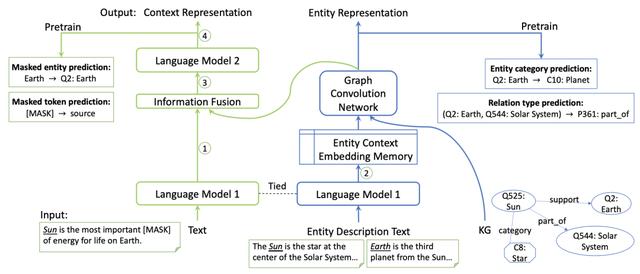 文章插图
文章插图
可以看出 , 语言模型得到的信息会首先对输入文本以及entity/relation的描述信息进行编码 , 以得到对应的表示;之后语言模型得到的entity embedding会被送给R-GAT模型以聚合邻居节点的信息 , 以得到更强的entity表示;然后该部分信息会被输入给语言模型继续融合并编码 , 以得到强化的文本表示信息;
- 快递|国家邮政局:推动邮政快递行业由劳动密集型向知识密集型发展
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 双行合一|关于Word我们要了解的知识(12)
- 经济总量|美国经济总量世界第一,究竟是靠哪些产业支撑的呢?看完长知识了
- 电脑知识|北大青鸟:零基础学电脑从哪里入手
- 打击|莫让知识产权侵权“打击”了家电行业的创新积极性
- 为什么手机大厂们都喜欢搞子品牌?看完算长知识了
- 今天才发现,微信长按2秒,还有6个隐藏功能,涨知识了
- 学习大数据需要具备哪些基础知识,以及应该重视哪些环节
- 又爆新作!阿里甩出架构师进阶必备神仙笔记,底层知识全梳理