Python爬虫教程,爬取网易云的音乐
在开始之前 , 做一点小小的说明哈:
- 我只是一个python爬虫爱好者 , 如果本文有侵权 , 请联系我删除!
- 本文需要有简单的python爬虫基础 , 主要用到两个爬虫模块(都是常规的)requests模块selenium模块
- 建议使用谷歌浏览器 , 方便进行抓包和数据获取 。 私信小编01即可获取大量Python学习资料
 文章插图
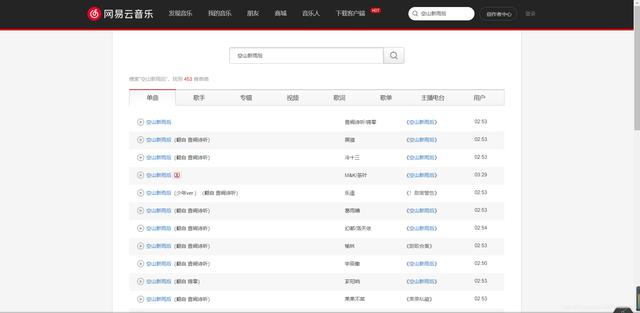
文章插图这时我们来观察网页的url , 可以发现s=后面就是我们搜索的关键字
 文章插图
文章插图当我们换一首歌 , 会发现也是这样的 , 正好验证了我们的想法
 文章插图
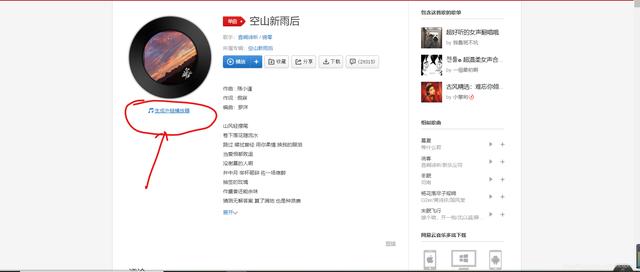
文章插图所以下一步让我们点进去一首歌 , 然后进行播放 , 看看能否直接获取音乐文件的url , 如果能 , 那么直接对url进行requests.get访问 , 我们就能拿到.mp3文件了点进第一首“空山新雨后” , 我们可以看到有一个“生成外链播放器”
 文章插图
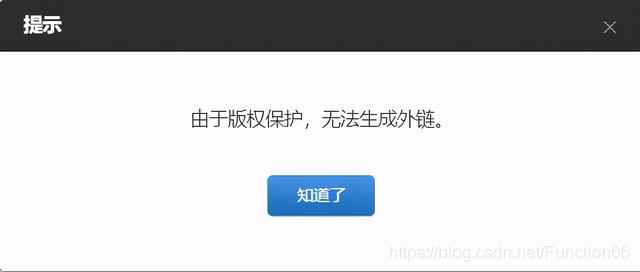
文章插图看到这个 , 我心中一阵激动 , 仿佛就要大功告成;于是我满怀开心的点了一下 , 结果 。。。
 文章插图
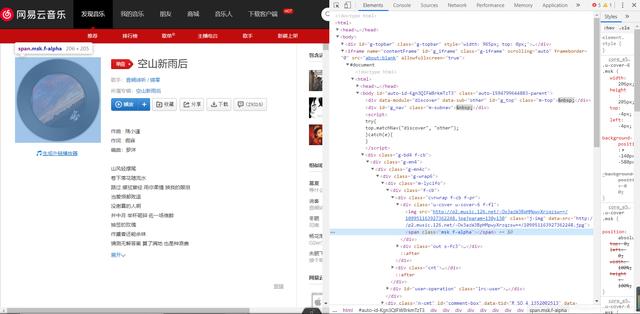
文章插图好吧 , 不过我们不能放弃 , 来我们分析一下网页但当我们定位到两个最有可能出现外链的地方时 , 发现什么都没有
 文章插图
文章插图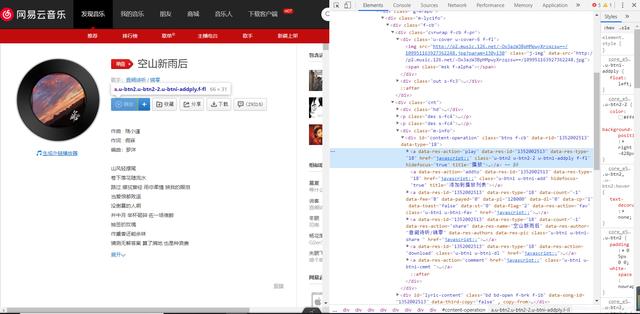 文章插图
文章插图不过作为“规格严格 , 功夫到家”的传承者 , 我不能放弃啊 , 于是我又打开了抓包工具按照常规套路 , 我们定位到XHR
 文章插图
文章插图点击播放后 , 出现了一大堆东西 , 我们要做的就是找到其中的content-type为audio一类的包功夫不负有心人 , 在寻找了一(亿)会儿后 , 我找到了
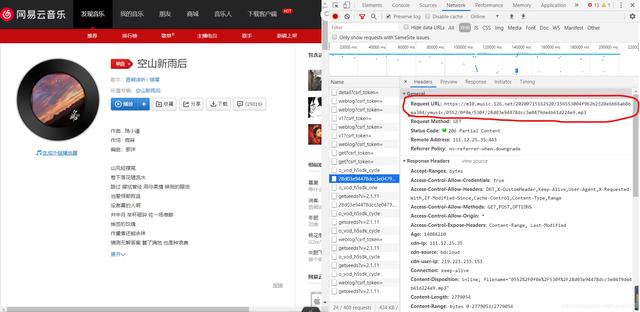 文章插图
文章插图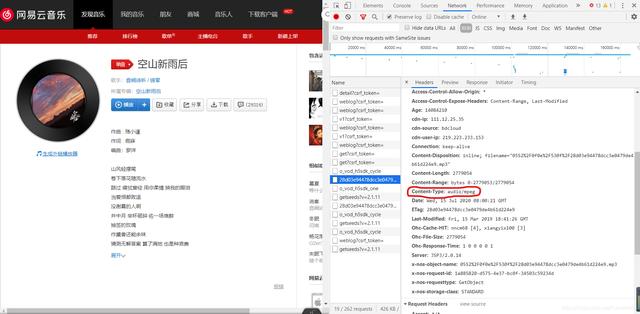 文章插图
文章插图于是我又满怀开心的复制了这个包对应的Request-URL粘贴后访问这个url , 结果非常满意 , 这就是我一直在找的url
 文章插图
文章插图现在我把那个url贴出来
#导入requests包import requests#进行UA伪装headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}#指定urlurl = ''#调用requests.get方法对url进行访问 , 和持久化存储数据audio_content = requests.get(url=url,headers=headers).content#存入本地with open('空山新雨后.mp3','wb') as f :f.write(audio_content)print("空山新雨后爬取成功!!!")Part3 更高级的看到这里 , 你可能会想 , 为啥根本没用selenium模块呢?能不能直接爬取任何一首我想要的歌 , 而不用每首都去费心费力的找一个url呢?当然可以哒!其实网易云在线播放每首歌曲时 , 都有一个外链地址 , 这是不会变的 , 跟每首歌的唯一一个id绑定在一起 , 每首歌audio文件的url如下:url = '' + 歌曲的id值 + '.mp3'id值的获取也很简单 , 当我们点进每首歌时 , 上方会出现对应的网址 , 那里有id值 , 如下图: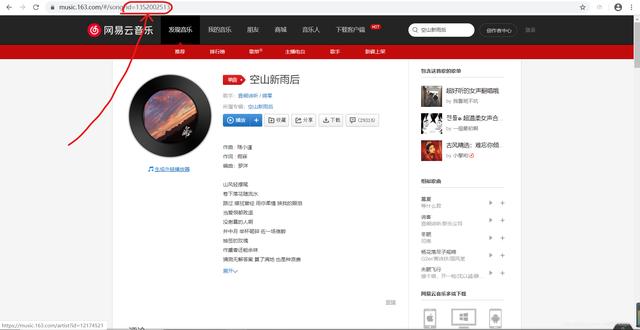 文章插图
文章插图所以只需把上面程序中的url改成新的url即可如果还想要更好的体验效果 , 实现在程序里直接搜索歌曲 , 拿到id值 , 就需要用到selenium模块为什么用selenium而不用xpath或bs4?因为搜索页面的数据是动态加载出来的 , 如果直接对搜索页面的网页进行数据解析 , 就拿不到任何数据;以我目前的技术 , 就只能想到使用万能的selenium模块 , 下面大概说明一下步骤:
- 进行selenium无可视化界面设置
from selenium.webdriver.chrome.options import Optionschrome_options = Options()chrome_options.add_argument('--headless')chrome_options.add_argument('--disable-gpu')
- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- 随身携带「Windows」Windows To Go制作教程
- Python中文速查表-Pandas 基础