在TPU上运行PyTorch的技巧总结( 二 )
网络的输入是具有6个通道的512 x 512图像 。我们测量了在训练循环中每秒处理的图像 , 根据该指标 , 所描述的TPU配置要比Tesla V100好得多 。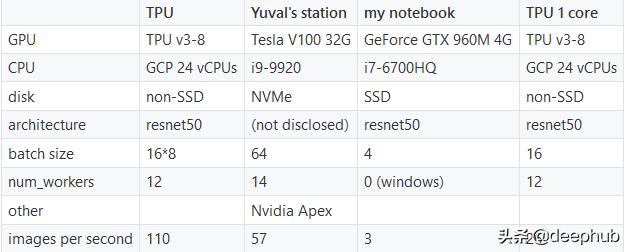 文章插图
文章插图
如上所述(不带DataParallel)的单核TPU的性能为每秒26张图像 , 比所有8个核在一起的速度慢约4倍 。
由于竞争仍在进行中 , 我们没有透露Yuval使用的体系结构 , 但其大小与resnet50并没有太大差异 。但是请注意 , 由于我们没有运行相同的架构 , 因此比较是不公平的 。
尝试将训练映像切换到GCP SSD磁盘并不能提高性能 。
总结总而言之 , 我在PyTorch / XLA方面的经验参差不齐 。我遇到了多个错误/工件(此处未全部提及) , 现有文档和示例受到限制 , 并且TPU固有的局限性对于更具创意的体系结构而言可能过于严格 。另一方面 , 它大部分都可以工作 , 并且当它工作时性能很好 。
最后 , 最重要的一点是 , 别忘了在完成后停止GCP VM! 文章插图
文章插图
作者:Zahar Chikishev
deephub翻译组
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 行业|现在行业内客服托管费用是怎么算的
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 长安|长安傍上华为这个大腿,市值暴涨500亿!可见华为影响力之大?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰