金钱能让人更快乐吗?手把手教你用机器学习找到答案
导读:本文通过“金钱能让人更快乐吗?”等实操案例带你了解基于实例的学习和基于模型的学习 。
作者:Aurélien Géron
来源:华章科技 文章插图
文章插图
一种对机器学习系统进行分类的方法是看它们如何泛化 。 大多数机器学习任务是要做出预测 。 这意味着系统需要通过给定的训练示例 , 在它此前并未见过的示例上进行预测(泛化) 。 在训练数据上实现良好的性能指标固然重要 , 但是还不够充分 。 真正的目的是要在新的对象实例上表现出色 。
泛化的主要方法有两种:基于实例的学习和基于模型的学习 。
01 基于实例的学习我们最司空见惯的学习方法就是简单地死记硬背 。 如果以这种方式创建一个垃圾邮件过滤器 , 那么它可能只会标记那些与已被用户标记为垃圾邮件完全相同的邮件—这虽然不是最差的解决方案 , 但肯定也不是最好的 。
除了完全相同的 , 你还可以通过编程让系统标记与已知的垃圾邮件非常相似的邮件 。 这里需要两封邮件之间的相似度度量 。 一种(基本的)相似度度量方式是计算它们之间相同的单词数目 。 如果一封新邮件与一封已知的垃圾邮件有许多单词相同 , 系统就可以将其标记为垃圾邮件 。
这被称为基于实例的学习:系统用心学习这些示例 , 然后通过使用相似度度量来比较新实例和已经学习的实例(或它们的子集) , 从而泛化新实例 。 例如 , 图1-15中的新实例会归为三角形 , 因为大多数最相似的实例属于那一类 。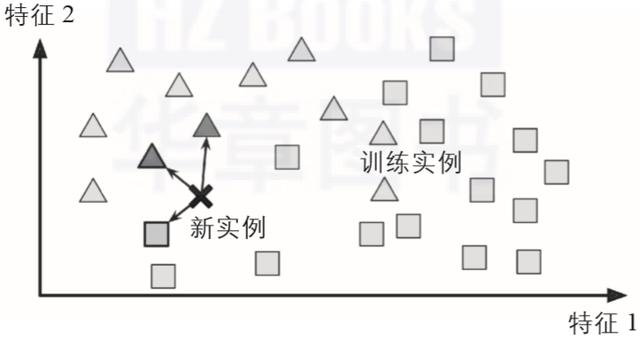 文章插图
文章插图
▲图1-15:基于实例的学习
02 基于模型的学习从一组示例集中实现泛化的另一种方法是构建这些示例的模型 , 然后使用该模型进行预测 。 这称为基于模型的学习(见图1-16) 。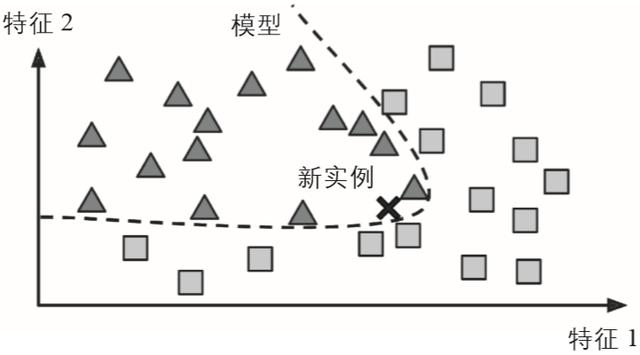 文章插图
文章插图
▲图1-16:基于模型的学习
举例来说 , 假设你想知道金钱是否让人感到快乐 , 你可以从经合组织(OECD)的网站上下载“幸福指数”的数据 , 再从国际货币基金组织(IMF)的网站上找到人均GDP的统计数据 , 将数据并入表格 , 按照人均GDP排序 , 你会得到如表1-1所示的摘要 。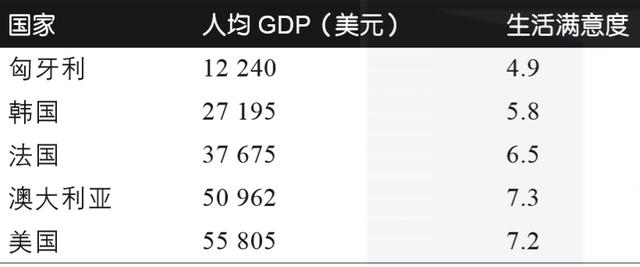 文章插图
文章插图
表1-1:金钱能让人更快乐吗?
让我们绘制这些国家的数据(见图1-17) 。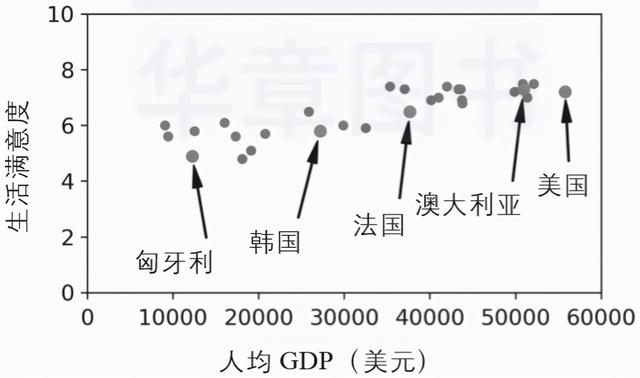 文章插图
文章插图
▲图1-17:趋势图
这里似乎有一个趋势!虽然数据包含噪声(即部分随机) , 但是仍然可以看出随着该国人均GDP的增加 , 生活满意度或多或少呈线性上升的趋势 。 所以你可以把生活满意度建模成一个关于人均GDP的线性函数 。 这个过程叫作模型选择 。 你为生活满意度选择了一个线性模型 , 该模型只有一个属性 , 就是人均GDP(见公式1-1) 。
公式1-1:一个简单的线性模型
生活满意度= θ0 + θ1×人均GDP
这个模型有两个模型参数:θ0和θ1 。 通过调整这两个参数 , 可以用这个模型来代表任意线性函数 , 如图1-18所示 。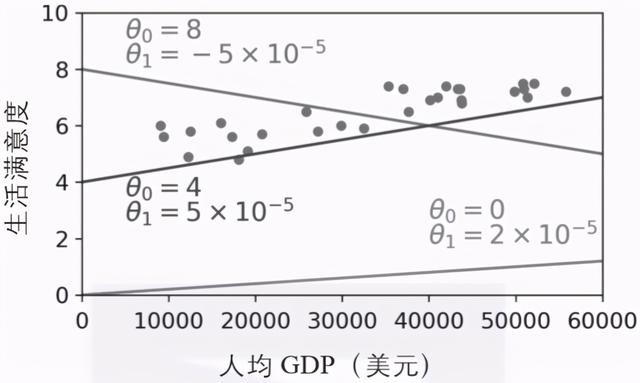 文章插图
文章插图
▲图1-18:一些可能的线性模型
在使用模型之前 , 需要先定义参数θ0和θ1的值 。 怎么才能知道什么值可以使模型表现最佳呢?要回答这个问题 , 需要先确定怎么衡量模型的性能表现 。 要么定义一个效用函数(或适应度函数)来衡量模型有多好 , 要么定义一个成本函数来衡量模型有多差 。
对于线性回归问题 , 通常的选择是使用成本函数来衡量线性模型的预测与训练实例之间的差距 , 目的在于尽量使这个差距最小化 。
这正是线性回归算法的意义所在:通过你提供的训练样本 , 找出最符合提供数据的线性模型的参数 , 这称为训练模型 。 在这个案例中 , 算法找到的最优参数值为θ0 = 4.85和θ1 = 4.91×10^(-5) 。
注意:令人困惑的是 , 同一个词“模型”可以指模型的一种类型(例如 , 线性回归) , 到一个完全特定的模型架构(例如 , 有一个输入和一个输出的线性回归) , 或者到最后可用于预测的训练模型(例如 , 有一个输入和一个输出的线性回归 , 使用参数θ0 = 4.85和θ1 = 4.91×10^(-5)) 。 模型选择包括选择模型的类型和完全指定它的架构 。 训练一个模型意味着运行一种寻找模型参数的算法 , 使其最适合训练数据(希望能对新的数据做出好的预测) 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 痛点|首个OTA智能社区诞生 解决行业四大痛点
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 国产手机|国产手机新品频发,果粉们你们还能忍得住吗?
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 蛋壳公寓|官媒发声:绝不能让“割韭菜者”一跑了之!
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个