按关键词阅读: 当当网 隐私 泄露 漏洞 账户
还有其他研究人员将模仿学习扩展到复杂的类人运动和非琐碎设置中的游戏行为。从 Wasserstein 到 Gromov-Wasserstein,该论文工作是对 Dadashi 等人以及 Papagiannis 和 Li 的延伸,从而超越了专家和模仿者在同一域中的限制,并进入了生活在不同空间中的智能体之间的跨域设置。
跨域和形态的迁移学习。在 RL 中,不同域之间传递知识的工作通常会学习状态空间和动作空间之间的映射。Ammar 等人使用无监督流形对齐,在具有相似局部几何形状但假定可以获得手工制作特征的状态之间找到线性映射。最近在跨视点迁移学习和实施例不匹配方面的工作学习了不需要手工特性的状态映射,但假设可以从两个领域获得成对和时间对齐的演示。
此外,Kim 等人和 Raychaudhuri 等人提出了从未配对和未对齐任务中学习状态映射的方法。所有这些方法都需要智能体任务,即来自两个域的一组专家演示,这限制了这些方法在现实世界中的适用性。Stadie等人提出将对抗学习和域混淆结合起来,在不需要智能体任务的情况下在智能体域学习策略,但他们的方法仅适用于小视点不匹配的情况。Zakka等人采用目标驱动的观点,试图模拟任务进程,而不是匹配细粒度的结构细节,以便在物理机器人之间转换。
相比之下,这篇论文的方法不依赖于学习智能体之间的显式跨域潜在空间,也不依赖于智能体任务。GromovWasserstein 距离使研究人员能够在没有共享空间的情况下直接比较不同的空间。现有基准测试任务假设可以访问来自两个智能体的一组演示,而这篇论文中的实验仅假设可以访问专家演示。
文章插图
文章插图
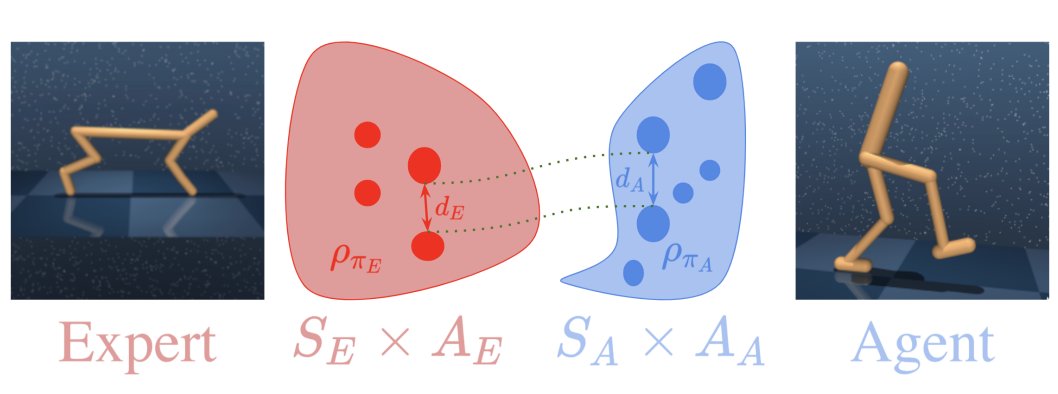
图注:Gromov-Wasserstein 距离使我们能够比较具有不同动态和状态-动作空间的两个智能体的平稳的状态-动作分布。我们将其用作跨域模仿学习的伪奖励。
文章插图
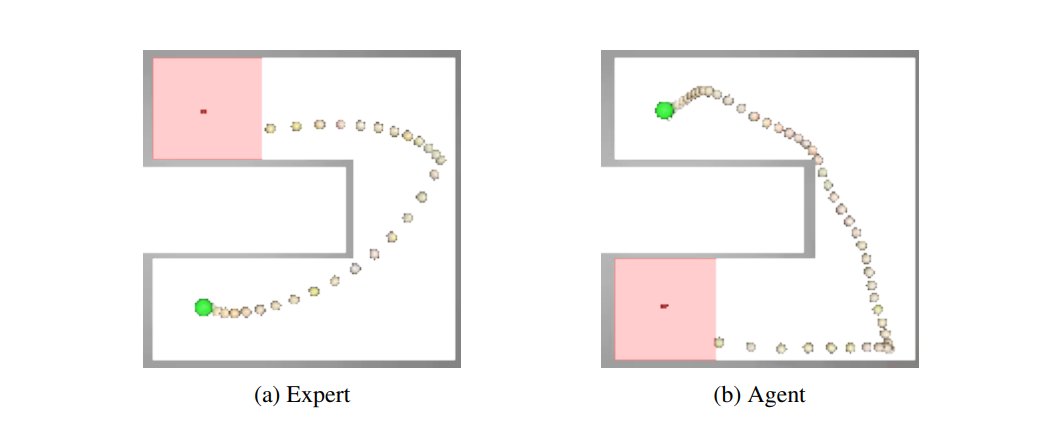
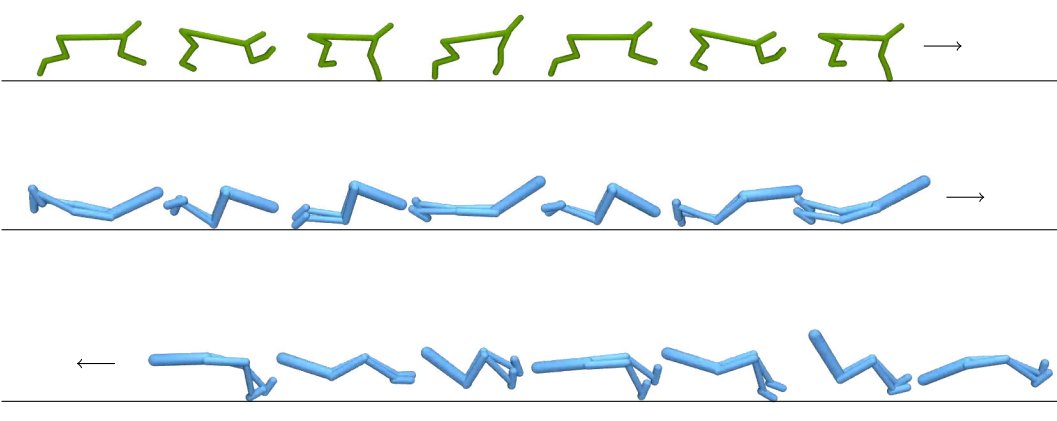
图注:给定专家域(a)中的单个专家轨迹,GWIL 在没有任何外部奖励的情况下恢复智能体域(b)中的最优策略。绿点表示初始状态位置,当智能体达到红色方块表示的目标时,事件结束。
1. 当智能体域是专家域的刚性变换时,GWIL能否恢复最优行为?这是可以的,论文的作者们用迷宫证明了这一点。
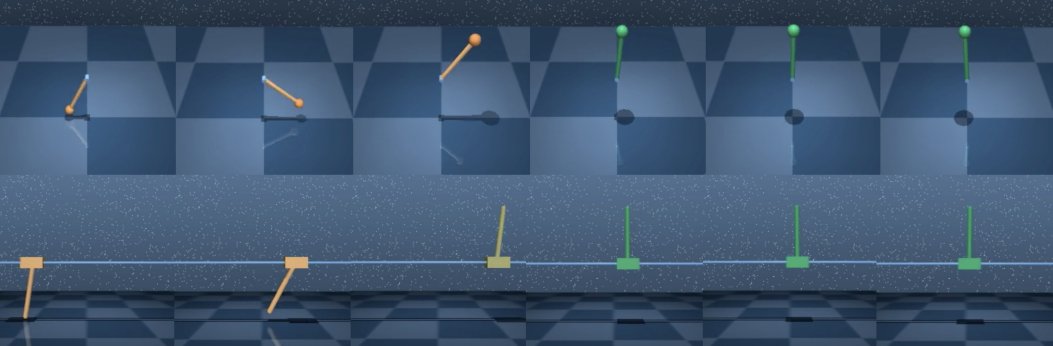
2. 当智能体的状态和行动空间与专家不同时,GWIL能否恢复最优行为?这也是可以的,本篇论文中,作者们展示了倒立摆(cartpole)和钟摆(pendulum)之间轻微不同的状态-动作空间以及步行者(walker)和猎豹(cheetah)之间显著不同的空间。
为了回答这两个问题,研究人员使用了在 Mujoco 和 DeepMind 控制套件中实现的模拟连续控制任务。该学习策略的视频可在论文的项目网站上访问。在所有设置中,作者在dE和dA的专家和智能体空间中使用欧几里得度量。
学习策略地址:https://arnaudfickinger.github.io/gwil/
文章插图
文章插图

文章插图
雷峰网
![]()
稿源:(雷锋网)
【傻大方】网址:/c/111cC1592021.html
标题:rl|如何让人模仿猎豹走路?Stuart Russell提出基于最优传输的跨域模仿学习( 二 )