模型|重点!11个重要的机器学习模型评估指标( 四 )
AB – Concordant
BC – Discordant
因此 , 在这个例子中50%的一致案例 。 一致率超过60%会被视为好模型 。 在决定锁定客户数量时 , 通常不使用此指标标准 。 它主要用于测试模型的预测能力 。 像锁定客户数量的话 , 就再次采用KS图或者提升图 。 文章插图
文章插图
9. 均方根误差
RMSE是回归问题中最常用的评估指标 。 它遵循一个假设 , 即误差无偏 , 遵循正态分布 。 以下是RMSE需要注意的要点:
1.“平方根”使该指标能够显示很多偏差 。
2.此指标的“平方”特性有助于提供更强大的结果 , 从而防止取消正负误差值 。 换句话说 , 该指标恰当地显示了错误术语的合理幅度 。
3.它避免使用绝对误差值 , 这在数学计算中是极不希望看到的 。
4.有更多样本时 , 使用RMSE重建误差分布被认为更可靠 。
5.RMSE受异常值的影响很大 。 因此 , 请确保在使用此指标之前已从数据集中删除了异常值 。
6.与平均绝对误差相比 , RMSE提供更高的权重并惩罚大错误 。
RMSE指标由以下公式给出: 文章插图
文章插图
其中 , N是样本总数 。文章插图
10. 均方根对数误差
在均方根对数误差的情况下 , 采用预测和实际值的对数 。 基本上 , 正在测量的方差就是变化 。 预测值和真值都很庞大时不希望处理预测值和实际值存在的巨大差异话通常采用RMSLE 。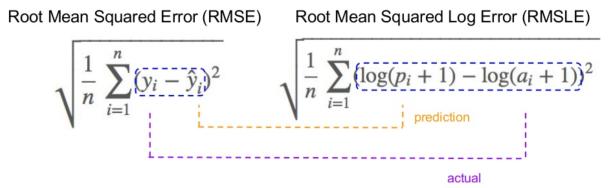 文章插图
文章插图
1.如果预测值和实际值都很小:RMSE和RMSLE相同 。
2.如果预测值或实际值很大:RMSE> RMSLE
3.如果预测值和实际值都很大:RMSE> RMSLE(RMSLE几乎可以忽略不计)文章插图
11. R-Squared/Adjusted R-Squared
已经知道RMSE降低时 , 模型的性能将会提高 。 但仅凭这些值并不直观 。
在分类问题的情况下 , 如果模型的准确度为0.8 , 可以衡量模型对随机模型的有效性 , 哪个准确度为0.5 。 因此 , 随机模型可以作为基准 。 但是在谈论RMSE指标时 , 却没有比较基准 。
这里可以使用R-Squared指标 。 R-Squared的公式如下: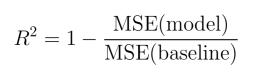 文章插图
文章插图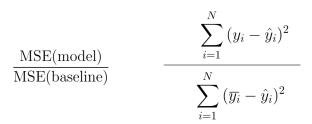 文章插图
文章插图
MSE(模型):预测值与实际值的平均误差
MSE(基线):平均预测值与实际值的平均误差
换言之 , 与一个非常简单的模型相比 , 回归模型可以说很不错了 , 一个简单的模型只能预测训练集中目标的平均值作为预测 。
Adjusted R-Squared调整后的可决系数(参考)
模型表现与baseline相同时 , R-Squared为0 。 模型越好 , R2值越高 。 最佳模型含所有正确预测值时 , R-Squared为1 。 但是 , 向模型添加新功能时 , R-Squared值会增加或保持不变 。 R-Squared不会因添加了对模型无任何价值的功能而被判“处罚” 。 因此 , R-Squared的改进版本是经过调整的R-Squared 。 调整后的R-Squared的公式如下: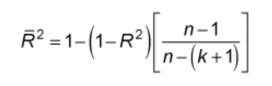 文章插图
文章插图
k:特征数量
n:样本数量
如你所见 , 此指标会考虑特征的数量 。 添加更多特征时 , 分母项n-(k +1)减小 , 因此整个表达式在增大 。
如果R-Squared没有增大 , 那意味着添加的功能对模型没有价值 。 因此总的来说 , 在1上减去一个更大的值 , 调整的r2 , 反而会减少 。
除了这11个指标之外 , 还有另一种检验模型性能 。 这7种方法在数据科学中具有统计学意义 。 但是 , 随着机器学习的到来 , 我们现在拥有更强大的模型选择方法 。 没错!现在来谈论一下交叉验证 。
虽然交叉验证不是真正的评估指标 , 会公开用于传达模型的准确性 。 但交叉验证提供了足够直观的数据来概括模型的性能 。
现在来详细了解交叉验证 。文章插图
12.交叉验证(虽然不是指标!)
首先来了解交叉验证的重要性 。 由于日程紧张 , 这些天笔者没有太多时间去参加数据科学竞赛 。 很久以前 , 笔者参加了Kaggle的TFI比赛 。 这里就不相信介绍笔者竞赛情况了 , 我想向大家展示个人的公共和私人排行榜得分之间的差异 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 智慧|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 建筑|国产第一台掘进机模型亮相“2020长江·三峡建筑产业博览会”
- 家庭|优酷大屏“酷喵”发布数字生活家庭战略,重点发力客厅场景
- 「数据架构」TOGAF建模:概念数据模型图
- 五种IO模型详解
- 老年人助听器选配需重点注意哪些?
- 用模型再骗20亿美金?又一个造车界大忽悠被扒
- 头文件|阿里面试题 | Nginx 所使用的 epoll 模型是什么?