实力反转,锐龙5默秒全!ZEN3架构为何能独孤求败?
 文章插图
文章插图
采用7nm ZEN3架构的AMD锐龙5000系列处理器一上市就受到了广大玩家的疯狂追捧 , 各大电商平台的抢购热潮此起彼伏 。 12核心的AMD锐龙9 5900X更是一U难求 , 可以说超过了历史上任何一代处理器产品上市的人气度 。 之所以锐龙5000销售如此火爆 , 当然是因为其性能表现实在惊人 , 游戏性能最多超越对手近30% , 而ZEN3架构到底是如何做到这一点的呢?
拒绝挤牙膏!ZEN3"硬核"升级亮点解析
AMD自从推出锐龙处理器以来 , 每一代的升级都抓住了市场需求的痛点 , 直击竞品的软肋 , 配合制程工艺升级的节奏、选择最适合的升级方式稳步提升处理器性能 , 总是能给用户与业界带来惊喜 。 从14nm ZEN到12nm ZEN+ , AMD将锐龙(线程撕裂者)处理器核心数量从16提升到了32 , 多线程性提升一倍以上 , 而从12nm ZEN+到7nm ZEN2 , 锐龙处理器不但IPC和频率大幅提升 , 同时消费级的AM4锐龙核心数量上限也从8提升到了16 , 线程撕裂者核心数量上限更是从32升级到了史无前例的64 , 在综合性能方面将对手远远甩在后面——这样的升级幅度 , 才叫做真正的硬核级"升级换代" 。
不过 , 就算综合性能强大如ZEN2 , 在面对十代酷睿游戏性能的时候 , 依然不能做到全面胜利 , 毕竟后者靠牺牲功耗和发热堆出了超高频率 , 在游戏中的表现不可小觑 。 AMD也很清楚 , ZEN3要实现全面反超 , 一味堆频率并不是一个好方案 , 毕竟提升频率的同时会带来功耗和发热的激增 , 很可能得不偿失(据说竞品下代产品为了再度提升频率 , 受制于功耗只能减少核心数量) , 必须要改进架构、在IPC方面有巨大突破才行 。 那么就让我们来看看ZEN3是怎么做到的 。
架构进化 , 效率提升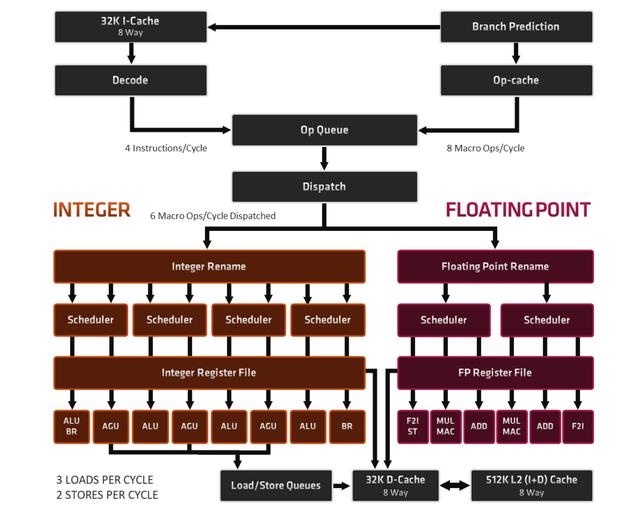 文章插图
文章插图
ZEN3在微架构方面进行了改进 , 目标就是大幅提升执行效率
1.前端增强:
主要设计目标:提供更快的抓取 , 特别是针对分支代码和空间占用大的代码 。
★L1分支目标缓冲区加倍到1024个条目 , 以便更好地预测延迟
★改进分支预测器带宽
★从错误预测中快速恢复
★"无气泡"预测功能使Back to Back预测更快 , 更好地处理分支代码
★更快的操作缓存取测序
★操作缓存区管道切换中的细粒度
2.执行引擎:
主要设计目标:减少延迟、扩大结构以提取更高的指令集并行性 。
★新的专用分支和st-整数数据选择器 , 现在每周期10次(比ZEN2增加3次)
★更大的整数窗口 , 比ZEN2增加了32
★减少选择整数与浮点操作的延迟
★浮点带宽增加2 , 现在总共有带宽为6的调度与发布
★浮点FMAC现在快了一个周期
3.负载库:
主要设计目标:更大的结构和更好的预取以支持增强执行引擎带宽 。
★总体上提供更高的带宽来满足更大/更快的执行资源需求
★更高的负载带宽 , 相比ZEN2增加1
★更高的存储带宽 , 相比ZEN2增加1
★更灵活的装载/存储操作
★改进了记忆依赖检测
★在TLB中增加了4 Table Walkers
这些专业说法可能对于一般玩家来讲看起来比较难懂 , 其实简单来说就是大幅提升了执行效率 , 同一时钟周期可以干更多的事情了 , 和ZEN2以及竞品相比就是同频性能大幅提升 。
专为游戏而进化的SOC架构 文章插图
文章插图
ZEN3采用单CCX 8核心/共享32 MB三级缓存的设计 , 相比ZEN2数据延迟更低 , 对提升游戏性能帮助巨大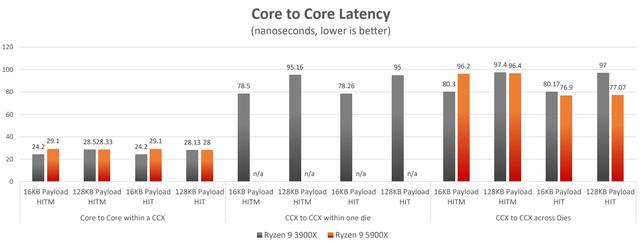 文章插图
文章插图
实测证明 , CCD到整合型CCX的变化大幅降低了ZEN3内部的综合数据延迟
之前我们也说了 , ZEN3的一个重要升级目标就是要在游戏性能方面完胜竞品 。 那么要做到这一点 , 除了提升IPC之外 , 还得降低数据延迟 , 包括核心与核心、核心与缓存、缓存与内存之间的延迟都得降低才行 。 因此 , ZEN3将ZEN2原有CCD中的所有核心统一成一个由4、6、8个连续核心组成的统一复合体(CCX)、将CCD中所有的三级缓存统一为最多32 MB的连续单元、核心/缓存之间的通信重新组成了环形系统 。 如此一来 , 游戏进程在处理器中会会直接面对32 MB缓存 , 而不是之前的16 MB 。 这样做 , 一方面相当于消除了跨CCX交换缓存数据带来的巨大延迟 , 另一方面也让最多8个核心可以共享32 MB缓存 , 效率更高 。 从实测来看 , 经过这样的改进之后 , AMD锐龙5000处理器的FCLK最高可达到2100 MHz , 和DDR4 4200可以实现1比1的频率比值 , 从而将内存延迟降低到50 ns以下 , 这相对于ZEN2最高1900 MHz FCLK确实提升了一大步 。 而内存延迟的巨幅降低 , 自然会带来明显的游戏帧速提升 。
- “树标提质”提升“软实力”数字经济时代创新载体大有可为
- 新机|realme和一加纷纷曝光新机:别看影响力小,实力可不容小觑
- 未入|5G手机市场重新洗牌!小米未入榜华为第二,第一实力依然很强
- Galaxy|反转?新报道称明年三星还会推出Galaxy Note系列机型
- 性价比|亮出隐藏实力!天玑800U+4800万后置三摄,实用性很暖心
- 一款非常特殊的锐龙迷你:还是12nm Zen+架构
- 锐龙5000搭配DDR4 4000
- 成员|千元机中的实力派再添新成员,三部千元机,一部更比一部强!
- vivo X50 Pro综合体验:具有划时代意义的实力新机
- 中国低调民营运营商巨头,造低门槛5G套餐,实力赢恒大和支持