面试官:你说你看过ArrayList源码,那你说说ArrayList的初始容量
 文章插图
文章插图
以下环境是 JDK 1.8
ArrayList 的初始容量面试官:你看过 ArrayList 的源码?
Python 小星:看过
面试官:那你说下ArrayList 的初始容量是多少?
Python 小星:10
面试官:你确定!?
......
1、ArrayList源码 -- 构造器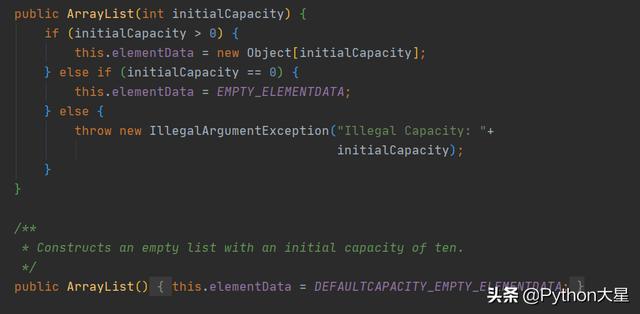 文章插图
文章插图
从源码里我们可以看到 , 无参构造函数 , 容量初始化为 0 , 有参构造函数的初始容量自定义 。
我们也可以做个测试验证 , 我们通过反射获取 elementData 的长度 , 即是 ArrayList 的容量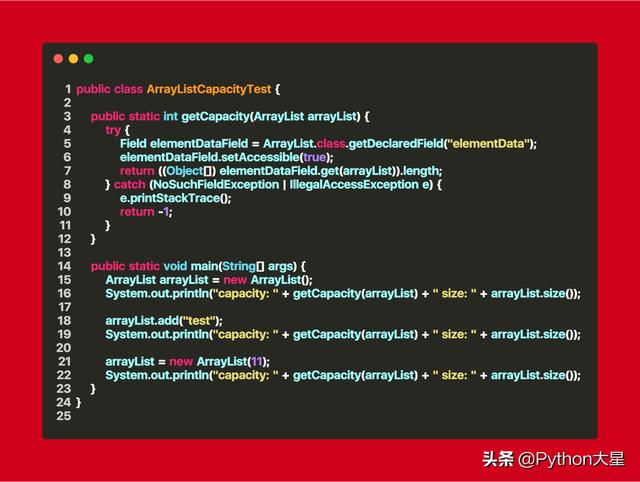 文章插图
文章插图
输出结果: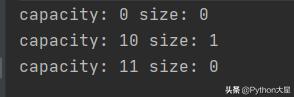 文章插图
文章插图
思考哈:为什么默认长度是 10 ?
hashmap 里默认 16 , 是为了 hash 算法 。 @Python大星 认为固定长度的数组初始容量不需要考虑 hashmap 里的hash冲突 , 取 10 可能是不大不小的值 , 然后一直引用下来 。 就像你说为什么数组的下标都是从 0 开始 , 而不是从 1 开始 , a [0] 就是偏移为 0 的位置 。 a [k] 就表示偏移 k 个元素类型大小的位置 , 少做一步减法 , 就一直被继承下来 , 无论是 C语言、Java语言 或者 Python 语言 。
知道的小伙伴欢迎在评论下留言 , 也许无形中帮助了很多迷茫的人 。
ArrayList 是“动态数组”-- 扩容1、“动态”体现在 ArrayList的自动扩容上
ArrayList 如何完成一次扩容?
场景:ArrayList 初始容量是 10, 如果再 add 一个元素 , 会怎样?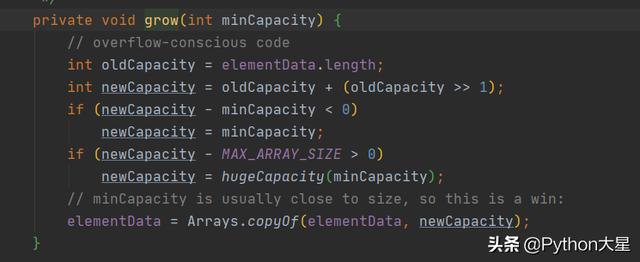 文章插图
文章插图
我们可以看到 JDK8 相比之前做了一点优化 , 使用了 >> 位运算
数组会按照 10 + 10 * 0.5 = 15 扩容(把原来的数组复制到另一个内存空间更大的数组中) , 扩容后再把指向原数的地址换到新数组 。 文章插图
文章插图
ArrayList、LinkedList、Vector 的区别?① Arraylist 和 Vector 是采用数组方式存储数据 , 所以插入数据慢 , 查找有下标 , 所以查询数据快
此数组元素数大于实际存储的数据以便增加插入元素 , 都允许直接序号索引元素 , 但是插入数据要涉及到数组元素移动等内存操作 ,
② Vector 本身所有方法都是用 synchronized 修饰的 , 线程安全 , 所以性能上比 ArrayList 要差
③ LinkedList 使用双向链表实现存储
按序号索引数据需要进行向前或向后遍历 , 查找较慢 , 但是插入数据时只需要记录本项前后项即可 , 插入数据较快 。
为什么说 ArrayList 不是线程安全?1、测试 文章插图
文章插图
输出结果:999
可以看出和我们预期的不一致 。
 文章插图
文章插图
在 add 操作分 2 步 :
① 判断 elementData 数组容量是否满足需求
② 在 elementData 对应位置上设置值
在多个线程进行 add 操作时可能会导致 elementData 数组越界 。
elementData [size++] = e 设置值的操作同样会导致线程不安全 。 从这儿可以看出 , 这步操作也不是一个原子操作 , 线程不安全 。
LinkedListLinkedList 内部是双向链表结构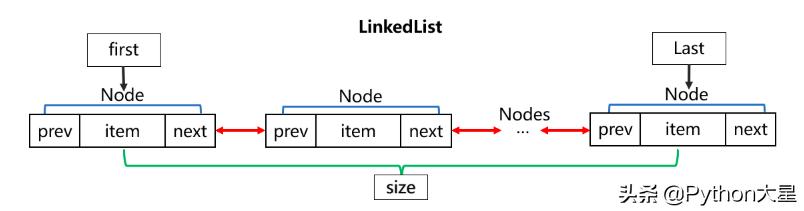 文章插图
文章插图
面试官:LinkedList 为什么说查找慢?它是怎么查找的?
Python 小星:因为它是链表结构 , 从表头开始遍历 , 所以当查找元素在链表后面 , 会比较慢
面试官:好的 。 回去等通知!
废话不多说 , 我们看下源码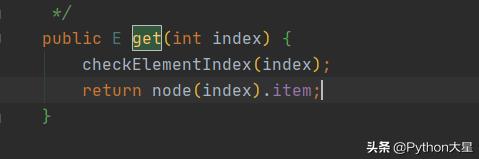 文章插图
文章插图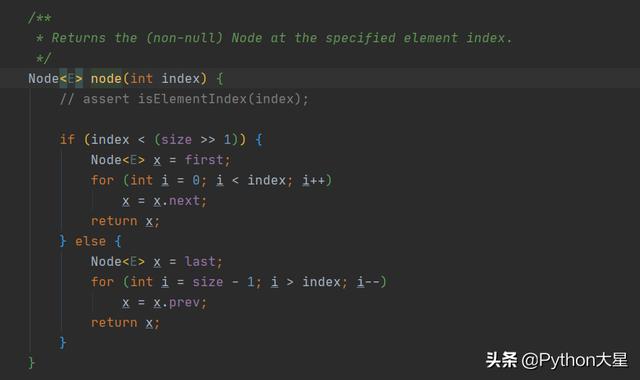 文章插图
文章插图
从第二张图中我们可以看出:
链表中的 index 只是标记元素的相对于链表头部(first 指向的)node 的个数, 这样在根据 index 查询时 , 可以根据 index 和 size 的关系 , 提高查询性能 。 当 index 大致在链表的前半部分时(index <(size>> 1)) , 从链表的首部开始遍历显然更快 , 而当 index 大致在链表的后半部分时(index > (size >> 1)) , 从链表的尾部开始遍历显然更快 , 这样就使得查找次数从 n 次将为了 n/2 次 , 虽然查找算法的时间复杂度还是 O (n) 。
我们都知道 LinkedList 是链表结构 , 那到底是单向链表还是双向链表?
- 蛋壳公寓|官媒发声:绝不能让“割韭菜者”一跑了之!
- 表达|重磅!2021世界安防博览会官方宣贯会正式召开,百余家企业表达参展意愿
- 公司|LVMH首席数字官跳槽至加密数字钱包公司Ledger
- 成为佛山移动服务体验官 表白留言赢取百元话费
- Store|在BlueMail的App Store反垄断案中 法官作出有利于苹果公司的判决
- 正式|首批体验官正式招募!仰望高端定制,OriginOS玩法大搜罗
- 全新|首批支持5款机型,vivo开启OriginOS首批体验官招募
- 全新|OriginOS招募首批体验官,网友:先冲为敬
- 无人|无人维护?官方打脸:Element UI for Vue 3.0 来了!
- 代言人|OPPO官宣“周冬雨”成为新代言人,周冬雨排列难道会被用上?