按关键词阅读:
文章插图
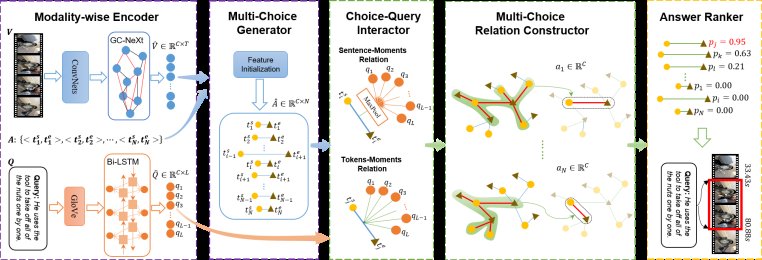
RaNet一共包含5个部分:(1)多模态的特征编码模块;(2)候选视频片段的生成模块;(3)候选视频片段和查询语句的交互模块;(4)不同视频片段的关系构建模块;(5)结果选择模块。
- 特征编码模块中,研究者们采用了在时序动作检测(Temporal Action Localization)中表现优异的GC-NeXt来获取视频序列中的时序信息,使用双向的LSTM来获取语言信息的长时间依赖。
- 候选视频片段生成模块中,研究者们借鉴了之前工作2D-TAN的方式,构建了一个二维的时序网格图,每一个小网格都代表一个候选视频片段,其特征是由起始时间帧的特征和终止时间帧的特征串联而得。
文章插图
- 视觉语言交互模块中,研究者们同时构建了视频片段-句子层面的关系和视频片段-单词层面的关系。对于视频片段和句子的关系,研究者们之间对语言特征进行max-pooling,然后和视频片段特征进行点乘。对于视频片段和单词的关系,研究者们通过语言特征和视频片段特征首先构建出一个注意力权重矩阵,然后再与视频片段特征交互,动态地生成query-aware的视频片段表征。这种粗粒度和细粒度结合的方式能够充分地交互视觉和语言两种模态之间的信息。
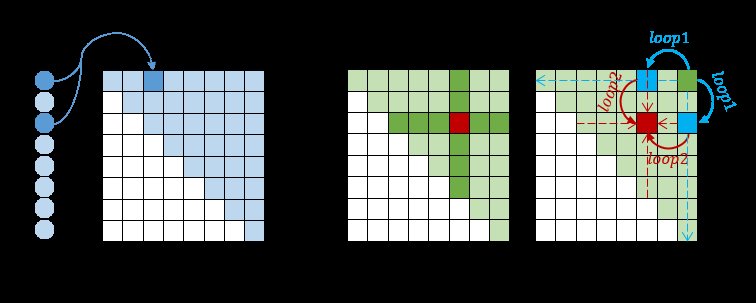
- 视频片段关系构建模块中,研究者们将每个候选视频片段视作图的点,将这些视频片段之间的关系视作图的边,构建了视频片段关系的图网络模型。考虑到重叠比较高的视频片段关联性更强,研究者们在构建图时仅考虑了和当前候选视频片段具有相同起始时间或者终止时间的视频片段,在网格图中就是一种十字架的形式。这样构建图的方式不仅可以减少不相关视频片段带来的噪声影响,还能有效提高模型的效率。
- 结果选择模块中,研究者们采用一个卷积层和sigmoid激活层为每个候选视频片段进行打分,根据得分从大到小排序,选择top-1或者top-5作为最终的预测视频片段。
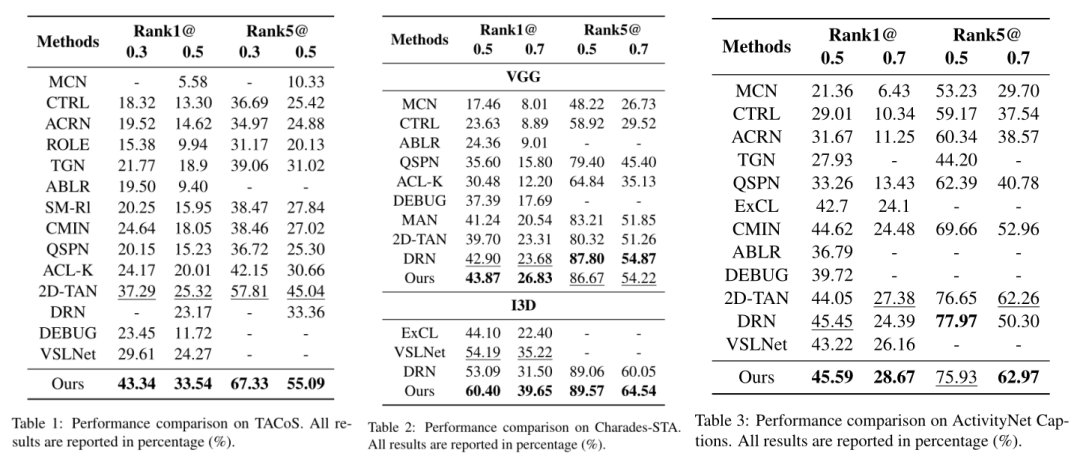
文章插图
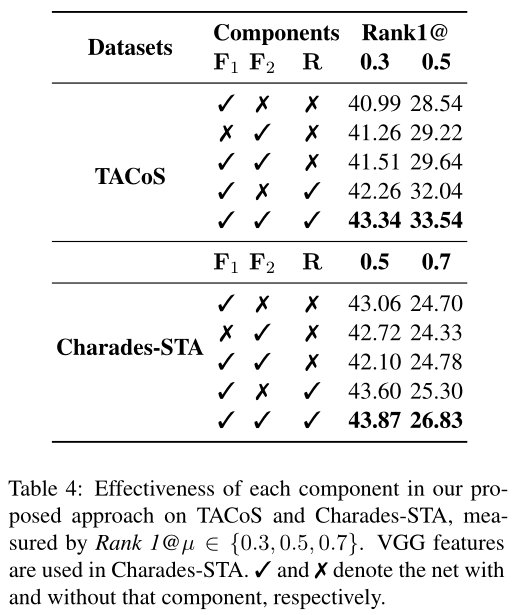
文章插图
文章插图
文章插图
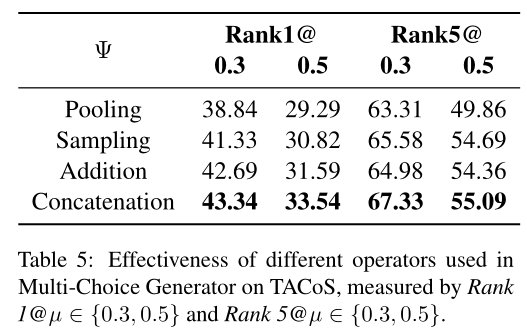
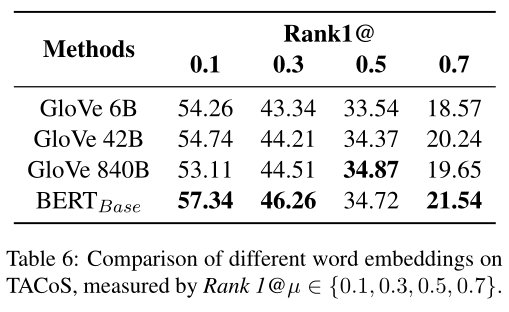
不同word embeddings的影响:
为了探寻不同的词向量编码对实验结果对的影响,研究者们还比较了不同word embeddings的表现,发现越强的语言表征更有益于模型精准地定位视频片段。
文章插图
稿源:(雷锋网)
【傻大方】网址:http://www.shadafang.com/c/11159612A2021.html
标题:云从科技&上海交大的跨模态技术成果:探索多层关系的REMNLP 2021 | 研究者们( 二 )