按关键词阅读:
操作系统
自研
欧拉操作系统
openeuler
基础软件
开源
代码
欧拉
鸿蒙
华为
软件包
我们基于两个预训练V&L模型进行实验:VisualBERT (Li et al., 2019), ViLBERT (Lu et al., 2019)。
文章插图
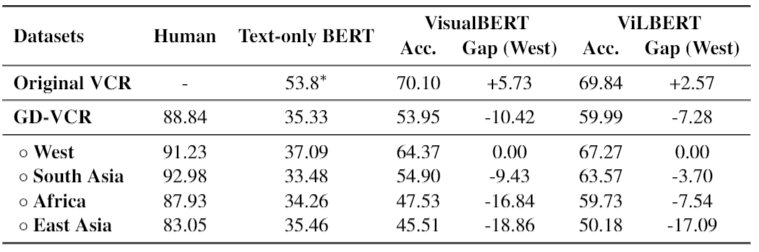
我们首先研究在 VCR 上训练的模型泛化到特定地区常识问题上的效果。首先,我们发现与西方图像相比,这两个模型在来自非西方地区的图像上的表现要差得多,差距大约为3-19%。此外,我们比较了模型和人类的表现。我们注意到,尽管人类可能不熟悉这种文化,但他们仍然比模型高出 30% 左右。这意味着人类更有能力将他们的常识转化并应用在地区多样化常识的理解过程中。然而目前的模型离这个水平还差很远。
我们后面从两个方面分析了产生这种表现差异的原因:
- 具有地区特征的场景:我们在 GD-VCR 中标注了图像的场景标签,所以我们可以借助标签将不同地区同一个场景的图片放在一起进行比较。我们观察到,对于经常涉及地区特征的场景(例如婚礼,节日等),性能差距要大得多,约为8%-24%。但是,对于一些世界上普遍存在且比较相似的场景,模型的性能差距仅为0.4-1.3%。

文章插图
(具有地区特征的场景与其他场景上模型表现差异对比。字体越大表示模型表现差异越大。红色场景差异大于8%,蓝色场景差异小于8%。)
- QA pair 的推理层次:在介绍推理层次之前,我们可以先思考模型什么时候会失败。我们认为可能有2种情景。“情景1”是,模型在早期甚至无法识别非西方图像的基本信息。“情景2”是,模型在基本视觉信息的识别上效果不错,但最终由于缺乏特定区域的常识而最终失败。
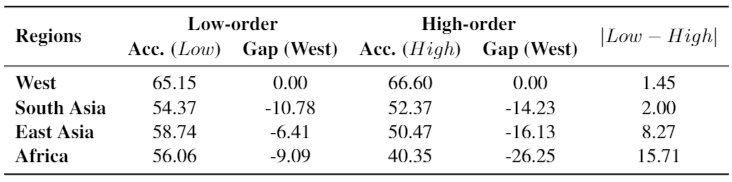
为了判断我们处于哪种情景,我们此外又注释了一些 low-order QA pairs。这些 low-order QA pairs 可以通过识别基本的视觉信息即可回答。例如,问题“[person3] 穿的什么?”就是一个 low-order QA pair。并且我们假设 GD-VCR 中的所有 QA pairs 都是 high-order QA pairs,因为它们涉及常识和更复杂的推理。low-order 和 high-order 分别对应低推理层次和高推理层次。
文章插图
(在low-order和high-order QA pairs上不同地区图片的模型表现差异)
我们用 VisualBERT 在这些 QA pairs 上评估。我们首先注意到模型在 low-order QA pairs 的效果好于 high-order QA pairs。此外,模型在不同地区 low-order QA pairs 的差异远小于 high-order QA pairs。这意味着该模型在基本视觉信息的问题上可以达到相似的性能,但是复杂常识推理增加了难度并扩大了差距。这意味着“情景2”更好地描述了这个状况。在文章中,我们构建了一个新的地区多样常识推理数据集 GD-VCR。我们在 GD-VCR 上评估模型性能,发现不同区域之间存在很大差异。最后我们分析了性能差异的来源:1) 具有地区特征的场景,和 2) QA pair 的推理层次。我们希望这篇文章不仅可以启发研究者去提高视觉常识推理模型在地区多样化场景上的泛化能力。我们还希望能借此文章拓宽研究人员的视野,以更加包容的态度对人工智能系统的世界通用性这一现实问题产生更多的思考。
[1] From Recognition to Cognition: Visual Commonsense Reasoning. Zellers et al., CVPR 2019.[2] Visually Grounded Reasoning across Languages and Cultures. Liu et al., EMNLP 2021.[3] SituatedQA: Incorporating Extra-Linguistic Contexts into QA. Zhang et al., EMNLP 2021.
文章插图
雷锋网

稿源:(雷锋网)
【傻大方】网址:http://www.shadafang.com/c/110c521B2021.html
标题:拓展你的视野!UCLEMNLP 2021Or ucla( 二 )