花束|干货分享:数据挖掘浅谈( 二 )
2.3 半监督学习半监督学习方法介于有监督学习和无监督学习之间,通常在数据不完整时使用。
2.4 强化学习强化学习不同于监督学习,它将学习看作是试探评价过程,以“试错”的方式进行学习,并与环境交互已获得奖惩指导行为,以其作为评价。也就是说,强调如何基于环境而行动,以取得最大化的预期利益。此时,系统靠自身的状态和动作进行学习,从而改进行动方案以适应环境。
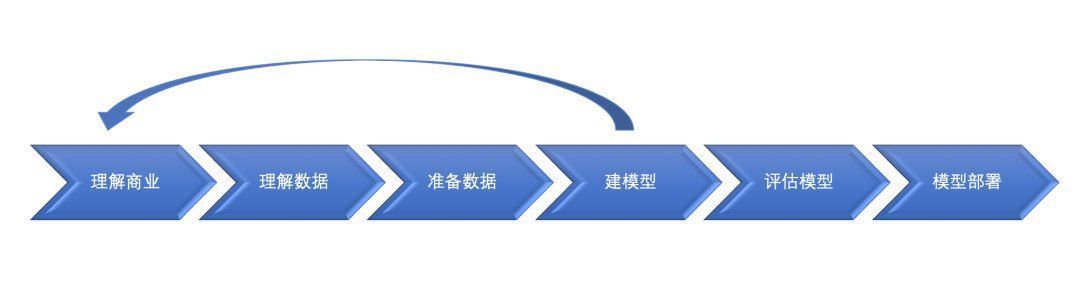
03 数据挖掘建模过程从数据本身来考虑,数据挖掘建模过程通常需要有理解商业、理解数据、准备数据、建模型、评估模型和部署模型6个步骤。
文章插图
3.1 理解商业理解商业算是数据挖掘中最重要的一部分,在这个阶段我们需要明确商业目标、评估商业环境、确定挖掘目标以及产生一个项目计划。简单地说,就是针对不同的业务场景,需要明白挖掘的目标是什么,需要达到什么样的效果。用大白话讲,就是你到底想干啥。
仍以鲜花店为例,为了提高销售额,店员可以帮助客户快速找到他感兴趣的花束,同时在保证用户体验的情况下,为其附加一个可接受的小饰品,比如花瓶、零食、香水等。
3.2 理解数据数据是挖掘过程的“原材料”,在数据理解过程中我们需要了解都有哪些数据,这些数据的特征是什么,可以通过对数据进行描述分析得到数据的特点。其中,了解有哪些数据尤为重要,其决定了后期工作进展的顺利程度。比如和花店有关的数据:
1)鲜花数据:鲜花名称、鲜花品类、采购时间、采购数量、采购金额等。
2)经营数据:经营时间、预定时间、预定品类、预定人数等。
3)其他数据:是否为节假日、用户口碑、竞争对手动向、天气情况等。
3.3 准备数据在数据准备阶段我们需要对数据作出清洗、重建、合并等操作。选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作。主要是为建模准备数据,可以从数据预处理、特征提取、特征选择等几方面出发,整理如下:1)缺失值:由于个人隐私或设备故障导致某些观测值在某些纬度上的漏缺,通常称为缺失值。缺失值存在可能会导致模型结果的错误,所以针对缺失值可以考虑删除、众数或均值填充等解决。
2)异常值:由于远离正常样本的观测点,它们的存在同样会对模型的准确型造成影响。可以通过象限图或3sigma(正态分布)进行判断,如果是,可以考虑删除或单独处理。
3)量纲不一致:模型容易受到不同量纲的影响,因此需要通过标准化方法(通常采用归一化、Normalization之类的方法)将数据进行转换。
4)维度灾难:当数据集中包含上百乃至上千万的变量时,往往会提高模型的复杂度,从而影响模型的运行效率,所以需要采用方差分析、相关分析、主成分分析等手段实现降维。
3.4 建模型一般情况下,预处理将占整个数据挖掘流程80%左右的时间。在保证数据“干净”的前提下,需要选出合适的模型。以下是常用的机器算法。1)分类模型:KNN、决策树、逻辑回归等。
2)回归模型:线性回归、岭回归、支持向量回归等。
3)无监督模型:k-means等。
数据挖掘中大部分模型都不是专为解决某个问题而特制的,模型之间相互不排斥。不能说一个问题只能采用某个模型,其他的都不能用。通常来说,针对某个数据分析项目,并不存在所谓的最好的模型,在最终决定选择哪种模型之前,各种模型都尝试一下,然后再选取一个较好的。各种模型在不同的环境中,优劣会有所不同。
3.5 评估模型评估阶段主要是对建模结果进行评估,目的是选出最佳的模型,让这个模型能够更好地反映数据的真实性。并不是每一次建模都能符合我们的目标,对效果较差的结果分析原因,偶尔也会返回前面的步骤对挖掘过程重新定义。比如,对于决策树或者逻辑回归,即使在训练集中表现良好,但在测试集中结果较差,说明该模型存在过拟合。
3.6 模型部署建立的模型需要解决实际的问题,它还包括了监督、产生报表和重新评估模型等过程。很多时候建模一般使用spss、python、r等,在建模的过程中只考虑模型的可用性,在生产环境中通常会利用Java或C++等语言将模型改写,从而提高运行性能。
祝大家情人节快乐!
作者:猫耳朵,专注于数据分析;“数据人创作者联盟”成员。
本文由@一个数据人的自留地 原创发布于人人都是产品经理,未经许可,禁止转载。
- 带货|揭秘爆款带货短视频的套路|超干货,值得收藏
- 软件|真正免费听歌和下载?分享无需VIP会员音乐软件,官方出品更可靠
- 客单价|占豪干货:付费和收费,才是最好链接人脉的方式
- 阿迪达斯|阿迪达斯因在Twitter上分享露骨图片以推广运动胸罩而受到批评
- 华为云|设计软件琳琅满目,分享几个避免踩雷
- 内存条|搭载国产长鑫颗粒,高性价比之选,金百达内存条使用分享
- ssd|小而美,快且光,K65 RGB Mini 机械键盘白色版分享
- iqoo|新机体验分享,告诉你为什么选iQOO 9 Pro
- 自媒体|自媒体干货分享,新手如何选择领域的三点小建议,最后一点比较重要
- 自媒体|赚钱不易,副业成刚需,分享3个适合普通人做自媒体短视频的方向