他们为图像和视频Transformer开发了稀疏的轴向注意力机制,可以更有效地使用计算,为视觉Transformer模型找到更好的标记图像方法,并通过检查视觉Transformer方法与卷积神经网络的操作方式相比,提高了对视觉Transformer方法的理解。将Transformer模型与卷积运算相结合,已在视觉和语音识别任务中显示出显著的优越性。
生成模型的输出质量也在大幅提高,这在图像的生成模型中表现得最为明显。
例如,最近的模型已经证明,仅给定一个类别(例如,输入“爱尔兰塞特”或“有轨电车”)就可以创建逼真的图像,也可以通过修复低分辨率图像,以创建一个看起来自然的高分辨率匹配图像(例如,输入“计算机,增强!”),甚至可以创建任意大小的自然场景。
另一个例子是,可以将图像转换为一系列离散标记,然后可以使用自回归生成模型以高保真度合成这些标记。

文章插图
图注:级联扩散模型的示例,该模型从给定类别生成新图像,然后将其用作种子来创建高分辨率示例:第一个模型生成低分辨率图像,其余模型对最终高分辨率图像执行上采样。
SR3 超分辨率扩散模型将低分辨率图像作为输入,并从纯噪声构建相应的高分辨率图像。
视频链接:https://iterative-refinement.github.io/assets/cascade_movie2_mp4.mp4
这些强大的功能背后,亦伴随着巨大的责任,因此谷歌表示会根据其 AI 原则仔细审查此类模型的潜在应用。
除了先进的单模态模型外,谷歌也开始注意大规模多模态模型的潜力。这些是迄今为止最先进的模型,因为它们可以接受多种输入模态(例如,语言、图像、语音、视频),并可以生成多种输出模态,例如,基于描述性的句子或段落生成图像,或用人类语言描述图像的视觉内容。
这是一个令人兴奋的方向,因为和现实世界一样,在多模态数据中有些东西更容易学习(例如,阅读并观看演示比仅仅阅读更有用)。因此,将图像和文本配对可以帮助完成多语言检索任务。并且,更好地理解如何将文本和图像输入配对,可以为图像描述任务带来更好的结果。
同样,对视觉和文本数据的联合训练也有助于提高视觉分类任务的准确性和鲁棒性,而对图像、视频和音频任务的联合训练可以提高所有模态的泛化性能。
此外还有一些迹象表明,自然语言可以用作图像处理的输入,告诉机器人如何与世界交互并控制其他软件系统,这预示着用户界面的开发方式可能会发生变化。这些模型处理的模态将包括语音、声音、图像、视频和语言,甚至可能扩展到结构化数据、知识图谱和时间序列数据。

文章插图
图注:基于视觉的机器人操作系统示例,该系统能够泛化到新任务。左图:机器人正在执行一项基于“将葡萄放入陶瓷碗中”指令的任务,而模型并未接受该特定任务的训练。右图:类似左图,但任务描述为“将瓶子放入托盘”。
这些模型通常使用自监督学习方法进行训练,其中模型从未经标记的“原始”数据的观察中学习,例如 GPT-3 和 GLaM 中使用的语言模型、自监督语音模型 BigSSL 、视觉对比学习模型 SimCLR 和多模态对比模型 VATT。自监督学习让大型语音识别模型得以达到之前的语音搜索自动语音识别 (ASR) 基准的准确度,同时仅使用 3% 的带注释训练数据。
这些趋势令人兴奋,因为它们可以大大减少为特定任务启用机器学习所需的工作量,并且由于使得在更具代表性的数据上训练模型变得更容易,这些数据更好地反映了不同的亚群、地区、语言,或其他重要的表示维度。
所有这些趋势都指向训练功能强大的通用模型的方向,这些模型可以处理多种数据模式,并解决成千上万个任务。通过构建稀疏性模型,使得模型中唯一被给定任务激活的部分,仅有那些为其优化过的部分,从而这些多模态模型可以变得高效。
Jeff Dean表示,在接下来的几年里,谷歌将基于Pathways架构追求这一愿景。
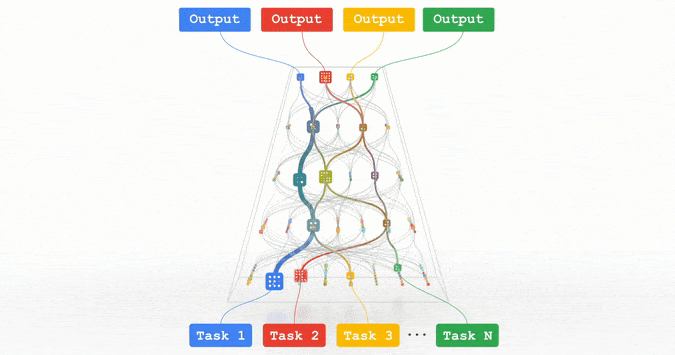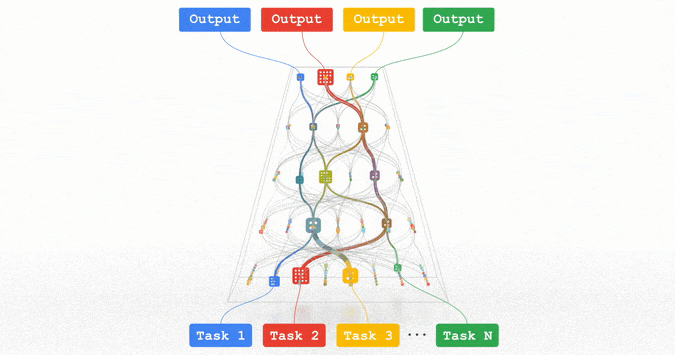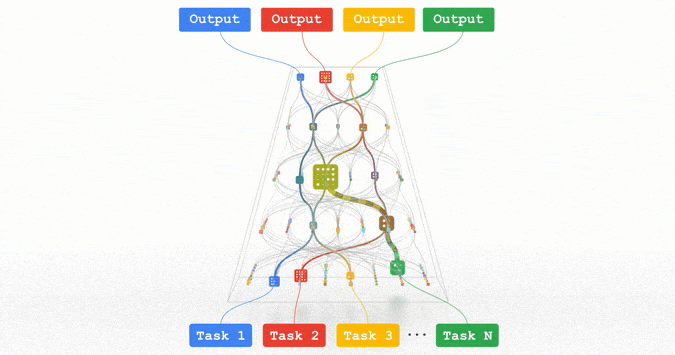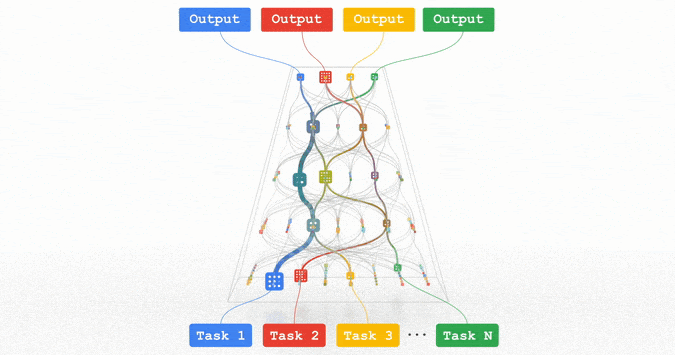
文章插图
Pathways:谷歌正在努力的统一模型,可以泛化至数百万个任务。
- 安卓|谷歌发布Android 13开发者预览版,首批适配多款谷歌手机
- Google|先有谷歌后有脸书,傲慢正在一步步瓦解美国的优势,将加速其衰落
- pi|安卓13来了!谷歌Android 13首个开发者预览版发布
- iPad|谷歌为iPad用户操碎了心
- cm英国批准谷歌淘汰Cookie计划:已消除竞争担忧
- 自动驾驶|马斯克要开放自动驾驶给所有车企使用,和谷歌开源安卓然后断供华为是一个道理
- Google|为让安卓机与苹果一样流畅,ARM替谷歌出手,做了回“恶人”
- 安卓|ARM、谷歌一起动手,落后5年后,安卓机终于要跟上苹果步伐了
- 安卓谷歌正在开发单独的 UWB API,允许第三方安卓 App 使用
- Sidney|谷歌5号员工Ray Sidney否认是谷爱凌生父