趋势|谷歌大神 Jeff Dean 领衔,万字展望五大AI趋势( 二 )

文章插图
图丨级联扩散模型(cascade diffusion models)的例子,从一个给定的类别生成新的图像,然后使用这些图像作为种子来创建高分辨率的示例:第一个模型生成低分辨率图像,其余的执行向上采样(upsampling)到最终的高分辨率图像。

文章插图
图丨SR3 超分辨率扩散模型是以低分辨率图像作为输入,并从纯噪声中构建相应的高分辨率图像。
鉴于这些强大的功能背后,潜藏着的是巨大的责任,所以我们不得不仔细审查,这类模型的潜在应用是否违背我们的人工智能原则。
除了先进的单模态模型(single-modality models)外,大规模的多模态模型(multimodal models)也在陆续进入人们的视野。这些模型是迄今为止最前沿的模型,因为它们可以接受多种不同的输入模式(例如,语言、图像、语音、视频),而且在某些情况下,还可以产生不同的输出模式,例如,从描述性的句子或段落生成图像,或用人类语言简要描述图像的视觉内容。这是一个令人惊喜的研究方向,因为类似于现实世界,在多模态数据中更容易学习(例如,阅读一些文章并看时辅以演示比仅仅阅读有用得多)。因此,将图像和文本配对可以帮助完成多种语言的检索任务,并且更好地理解如何对文本和图像输入进行配对,可以对图像字幕任务(image captioning tasks)带来更好的改进效果。同样,在视觉和文本数据上的联合训练,也有助于提高视觉分类任务的准确性和鲁棒性,而在图像、视频和音频任务上的联合训练则可以提高所有模式的泛化性能。还有一些诱人的迹象表明,自然语言可以作为图像处理的输入,告诉机器人如何与这个世界互动,以及控制其他软件系统,这预示着用户界面的开发方式可能会发生变化。这些模型处理的模式将包括语音、声音、图像、视频和语言,甚至可能扩展到结构化数据、知识图和时间序列数据等等。

文章插图
图丨基于视觉的机器人操作系统的例子,能够泛化到新的任务。左图:机器人正在执行一项用自然语言描述为“将葡萄放入陶瓷碗中”的任务,而不需要对模型进行特定的训练。右图:和左图一样,但是有“把瓶子放在托盘里”的新的任务描述。
这些模型通常使用自监督学习(Self-supervised learning)的训练,在这种方法中,模型从观察到的“原始”数据中学习,而这些数据没有被整理或标注。例如,GPT-3 和 GLaM 使用的语言模型,自监督的语音模型 BigSSL,视觉对比学习模型 SimCLR,以及多模态对比模型 VATT。自监督学习允许大型语音识别模型匹配之前的语音搜索中的自动语音识别技术(Automatic Speech Recognition)的基准精度,同时仅使用 3% 的标注训练数据。这些趋势是令人兴奋的,因为它们可以大大减少为特定任务启用 ML 所需的努力。而且,它们使得在更有代表性的数据上训练模型变得更容易,这些数据可以更好地反映不同的亚种群、地区、语言或其他重要的表示维度所有这些趋势都指向训练能够处理多种数据模式并解决数千或数百万任务的高能力通用模型的方向。通过构建稀疏性模型,使得模型中唯一被给定任务激活的部分是那些针对其优化过的部分,由此一来,这。
些多模态模型可以变得更加高效。在未来的几年里,我们将在名为“Pathways”的下一代架构和综合努力中追求这一愿景。随着我们把迄今为止的许多想法结合在一起,我们期望在这一领域看到实质性的进展。
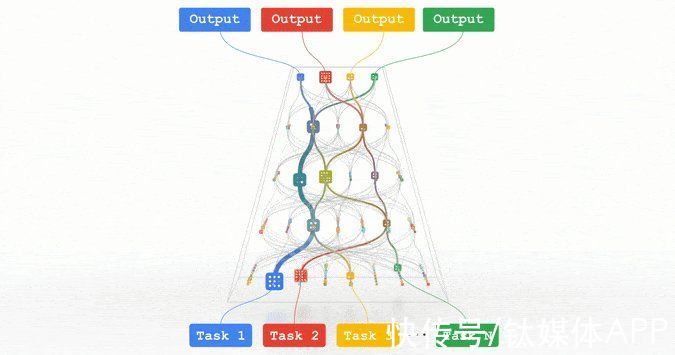
文章插图
图丨Parthway:我们正在朝着单一模型的描述而努力,它可以在数百万个任务中进行泛化。
趋势2:ML 的持续效率提高由于计算机硬件设计、ML 算法和元学习(meta-learning)研究的进步,效率的提高正在推动 ML 模型向更强的能力发展。ML 管道的许多方面,从训练和执行模型的硬件到 ML 体系结构的各个组件,都可以在保持或提高整体性能的同时进行效率优化。这些不同的线程中的每一个都可以通过显着的乘法因子来提高效率,并且与几年前相比,可以将计算成本降低几个数量级。这种更高的效率使许多关键的进展得以实现,这些进展将继续显著地提高 ML 的效率,使更大、更高质量的 ML 模型能够以更有效的成本开发,并进一步普及访问。我对这些研究方向感到非常兴奋!
- 安卓|谷歌发布Android 13开发者预览版,首批适配多款谷歌手机
- Google|先有谷歌后有脸书,傲慢正在一步步瓦解美国的优势,将加速其衰落
- pi|安卓13来了!谷歌Android 13首个开发者预览版发布
- iPad|谷歌为iPad用户操碎了心
- cm英国批准谷歌淘汰Cookie计划:已消除竞争担忧
- 自动驾驶|马斯克要开放自动驾驶给所有车企使用,和谷歌开源安卓然后断供华为是一个道理
- Google|为让安卓机与苹果一样流畅,ARM替谷歌出手,做了回“恶人”
- 阿里巴巴|人工智能要动摇科学家的地位?阿里达摩院发布十大科技趋势
- 安卓|ARM、谷歌一起动手,落后5年后,安卓机终于要跟上苹果步伐了
- 锂电池|Cloud PC:下一个数字化转型大趋势