具身|打破大模型的“空中城堡”,BMVC最佳论文Runner-Up得主谈多模态与具身学习( 三 )
上述研究中列举了高博士对声音空间信息的一些研究,而高博士的博士论文中除了研究声音的空间信息,还重点研究了声音的语义信息,探讨了如何同时利用声音和视觉更好地辅助学习视觉任务。那么如何理解声音的语义信息呢?

文章插图
这种思路可以联系到认知科学里面的“鸡尾酒会效应”,“我们在参加一个鸡尾酒宴会的时候,环境可能会很嘈杂,但是我们的注意力会很容易集中在与你进行谈话的那个人身上。同样,如果两个人在谈话,他们的声音可能是混在一起的,但如果通过结合人脸的视觉信息,就可以更好地将声音分离出来。”
高若涵的博士论文中也涉及了通过视觉信息进行声源分离,包括分离人说话的声音、乐器的声音,而这些就是对声音的语义信息的利用。
除此之外,在高若涵的“Listen to Look: Action Recognition by Previewing Audio”这篇论文中,他们还研究了“声音如何帮助动作识别”,这也是对声音语义信息的利用。
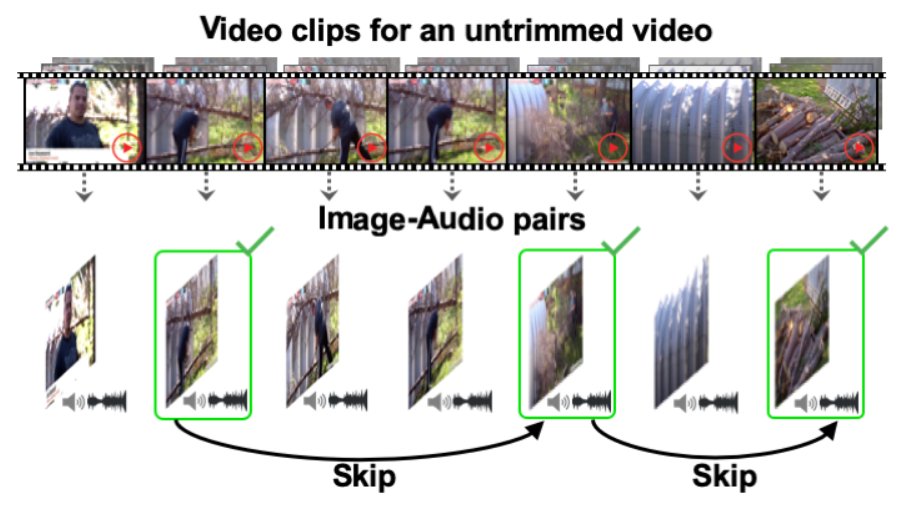
文章插图
论文地址:https://vision.cs.utexas.edu/projects/listen_to_look/
“比如给我一个没有处理过的很长的视频,我们要预测里面的动作,比如滑水、滑雪等等。之前在计算机视觉领域,人们一般通过分析提取视觉特征来进行预测。但如果视频非常长,就需要很多的计算资源。”
所以高若涵想到:其实声音也可以告诉我们语义上的信息。
在一个很长的视频里面,可以通过动作的声音信息识别,把注意力集中到某一个片段里,然后跳到这个片段去进行视觉识别。这样就可以极大提高视频动作识别的效率。
简言之,视觉和听觉可以进行交互达到感知增益。而无论是视觉感知还是听觉感知,都根植于身体行动,经验建构于具身交互。身体及其与环境的交互对学习活动具有重要的意义和影响,多模态学习离不开具身理论支撑。
首先,他和合作者们研究过一个听觉-视觉-导航三者结合的AI算法。“就是让一个智能体比如机器人在一个空间里通过听觉和视觉信息来找东西。比如有一个电话铃响了,机器人通过声音和视觉的感知,巡航到声音发生的地点。”

文章插图
论文地址:https://arxiv.org/pdf/2008.09622.pdf
具体而言,智能体学习多模态输入的编码以及模块化导航策略,以通过一系列动态生成的视听航点找到探测目标(例如,左上角房间的电话铃声)。例如,智能体首先在卧室里,听到电话铃响后,识别出它在另一个房间,并决定先离开卧室,然后它可以将电话位置缩小到餐厅,决定进入餐厅,然后找到电话。已有的分层导航方法依赖于启发式方法来确定子目标,而高若涵和合作者们提出的模型学习了一种策略来与导航任务联合设置航点。
- vivo|vivoX80Pro+曝光:打破传统束缚,性能与美的碰撞
- Linux|启中教育:直通车很烧钱?如何打破?
- 阿里巴巴|阿里自研赶跑外资,为马云省下几百亿,彻底打破外资垄断
- 光刻胶|徐州博康将光刻胶纯度提升10倍,打破日企垄断,华为加码3亿
- 芯片|清华大学不负众望,打破芯片领域技术限制,成功出货核心设备!
- 红米手机|打破技术封锁,K50电竞版加持国产A+原色屏,比DC调光更护眼
- 大数据|深度学习也能不玩大数据?小企业训练大模型有新解
- 用户|数据分析八大模型:同期群模型
- 华为|正式发布,华为官宣新消息!外媒:这是要彻底打破
- 半导体|又一领域打破垄断,良率99.99%,性能逼近三星,华为率先提供支持