【全生命周期|小内存大数据的解决方法】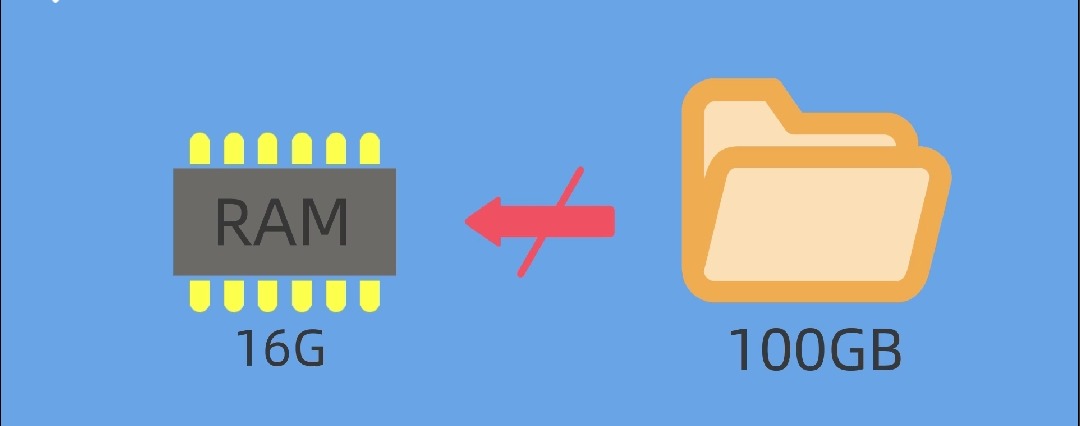
文章图片

文章图片
当你写了一个处理数据的软件它可能在小样本文件上运行的很好 , 但一旦加载大量真实数据后这个软件就会崩溃 。
原因在于你没有足够的内存 , 假设你是16GB的RAM , 你就无法一次载入100GB大小的文件 , 因为载入这么大的文件时操作系统在某个时刻就会耗尽内存 , 不能分配存储单元 , 你的程序也就会崩溃 。
为了防止这类情况发生 , 你可以启动一个大数据集群 , 需要做的是:第一步你要搞到一个计算机集群;第二步花一周时间搭建这个集群;第三步学习一套全新的API , 重写所有的代码 。
这样做可能很昂贵 , 而且大部分情况下我们也不必这样做 , 你需要一个简单而容易的解决方案在单机上处理你的数据 , 最小化环境搭建开销 , 尽可能地利用正在使用的代码库 。 实际上 , 大部分情况你都可以使用一些被称为核外计算的方法做到这样 。
为什么需要RAM , 计算机内存能让你读写数据 , 但是硬盘也可以读写数据 , 那为什么计算机还需要RAM呢?硬盘比RAM更便宜 , 所以它通常大到能够容纳下你所有数据 , 那为什么你的代码不能直接从硬盘读写数据呢?理论上讲这也行得通 , 但是即使是最现代化而且速度很快的SSD硬盘也比RAM慢太多 , 如果你想要实现快速计算数据就只能放在RAM中 , 否则你的代码运行时就会慢上150倍 。
资金方面的解决方案购买更多的DAM , 没有足够RAM时最简单的解决方案就是花钱来解决 , 购买一台计算机或者租一台云端的虚拟机 , 花钱购买硬件可以把你的数据读入RAM , 但这也是一个昂贵的解决方案 , 但当购买或者租用更多的RAM还不足以满足需求或者根本行不通时 , 下一步就应该考虑如何通过修改软件来减少内存使用了 。
技巧1:压缩
压缩意味着用一种不同的表达形式表示你的数据 , 这种形式能占用更少内存 , 有两种方式来压缩 , 无损压缩和有损压缩 。 这里的压缩不是使用ZIP或者gzip工具来压缩文件 , 你需要的是内存中的数据压缩表示形式 , 也就是数据中的两个值AVAILABLE和UNAVAILABLE , 我们可以不必将其存为10个或更多字节的字符串 , 你可以将其存为一个布尔值 , 用True或者False表示 , 这样你就可以只用1个字节来表示了 , 你甚至可以继续压缩至1位来表示布尔值 , 这样就继续压缩到了1个字节时的1/8大小 。
技巧2:分块
每次只加载所有数据里的某一块 , 当你需要处理所有数据而又无需把所有数据同时载入内存时 , 分块是很有用的 , 你可以把数据按块载入内存 , 每次计算一块的数据 , 假设你想搜索一本书里最长单词 , 你可以一次性将所有数据载入内存 , 但是在我们的例子中 , 这本书太大而不能完全载入内存 , 这时候你就可以一页一页地载入这本书 , 这样你使用的内存就大大减少了 , 因为你一次只需要把这本书的一页载入内存而最后得到的结果仍然是正确的 。
技巧3:当你需要数据的一个子集时索引会很有用 , 使用索引你可以在不同时刻加载数据的不同子集 , 你也可以用分块解决这个问题 , 每次加载所有数据过滤掉你不想要的数据 , 如果你只需要部分数据不要使用分块 , 最好使用索引 , 它可以告诉你到哪里能找出你关心的那部分数据 , 想象一下 , 你只想阅读书本中关于兔子的章节 , 如果你运用分块技术你得载入整本书 , 一页一页的载入 , 每页地搜寻兔子 , 但这要花很长时间才能完成 , 或者说你可以直接阅读这本书的索引部分 , 然后找到兔子的索引项 , 它可能会告诉你在第5、17页以及120页到123页可以读到相关内容 。 所以 , 现在你可以只读那几页 , 这样很有效 , 因为索引比整本书占用的空间要小很多 , 所以把索引载入内存找出相关内容所在就会更容易 。
最简单的索引技巧 , 最简单也最常用的实现索引的方法就是在目录里给文件恰当命名 , 如果你想要2019年3月份的数据你就只需要加载2019-Mar.csv这个文件而不用加载其他任何月份的数据 。
所以当RAM不够用时最简单的解决方法就是花钱买更多的RAM , 但是这个方案无法实现或者仍然不够用时你就需要使用压缩分块或者索引来解决 , 这些方法还出现在哪些软件包和工具中呢 , 欢迎你在评论区分享你的见解 。
- 中宣部版权管理局|中宣部版权局:全国首例制售盗版冰墩墩等玩偶被判一年
- 交货期|全球半导体交货期显著延长
- 网络安全|新版网络安全审查办法明日施行
- 红米手机|1999元起!Redmi K50全系售价曝光,干翻小米12
- 三星手机|三星手机的销量可以做到全球第一,为何在我们国内却进不了前五名?
- 小屏|全剧透,iPhoneSE3发布日期无悬念,小屏旗舰将进入新时代
- 全球财经网|亚太天能参与起草智能门相关技术团体标准,两度荣获标准起草单位称号
- LG|IPS屏缺陷已解决!LG推出全新IPS Black面板,能否对抗VA软屏?
- 全面屏|春季打造12代酷睿主机要注意,机电散你知道该怎么选择吗?
- AMD|红米K50电竞版全部细节及参数