挺进云端AI训练&推理双赛道!独家对话燧原科技COO张亚林:揭秘超高效率背后的“内功”( 二 )
于是 , 在燧原1.0阶段 , 刚成立18个月的燧原就推出了高性能云端训练产品 , 实现从0到1的破冰 。
进入2020年 , 燧原非但没有被疫情“黑天鹅”打乱阵脚 , 反而按计划顺利进入“从1到N”的燧原2.0阶段 , 循序渐进地完成新融资、云端训练集群方案商用落地、云端推理加速卡量产发布等重要节点 。 截至今日 , 燧原已累计融资13.4亿元 。
除了阶段进化、团队规模增长外 , 燧原的落地也更为多元 。 张亚林透露道 , 燧原目前针对互联网、垂直行业譬如教育、金融等方向正在进行头部客户的规模化落地 , “新基建”也正在快速铺陈 。
二、主流模型基准测试 , 表现超过GPU旗舰竞品技术理工出身 , 也可以充满文艺情怀 。
每个年末“压轴”出场的燧原旗舰产品发布会 , 其主题意义都很有文艺范儿 。
去年燧原云端训练计算卡云燧T10发布时 , 张亚林将主题定为“芯火燎原” , 希望云燧T10能一直开拓广袤的土地 。
如今云端推理计算卡云燧i10发布 , 主题变成了“芯汉灿烂” , 出自曹操《观沧海》中的名句“星汉灿烂 , 若出其里” 。 其中 , “灿烂”寓意更多后续产品 , 以此寄予对云燧i10在星空上持续闪耀的期待 。
通过对云端推理市场进行广泛调研和用户画像 , 燧原针对性地进行了极致能效提升、多用户虚拟化、工艺良率优化、散热方案增强等全方位产品打造 , 并完全独立重新设计了推理软件全栈和板卡系统 , 使云燧i10拥有出色的用户价值特性 。
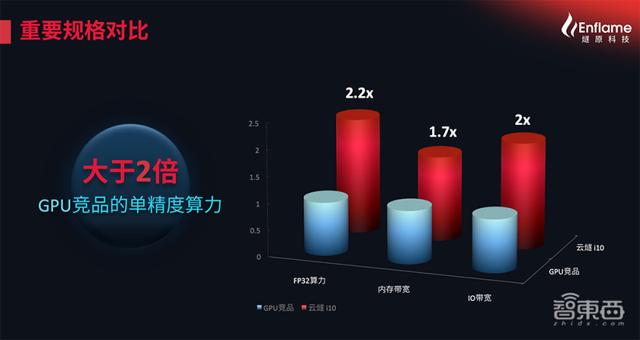
从燧原公布的基准测试表现来看 , 云燧i10可以说是不负所托 。 在主流的图像识别、视频增强、视频处理、内容审核、推荐等主流模型中 , 实测性能表现均超过GPU旗舰竞品 。
这得益于云燧i10的四个主要特征:
1、高算力、高精度:在150W单槽算力密度下 , FP32算力可达17.6TFLOPS , BF16/FP16算力可达70.4TFLOPS , 单精度算力可达GPU竞品的两倍以上;采用自主指令集 , 支持从FP32到INT8等多种精度;采用512GB/s高存储带宽和16GB本地存储 。
 文章插图
文章插图
2、高能效、高可靠性:智能功耗管理(APC)采用动态调频调压(DVFS)技术将功耗控制到接近但不超过最大值150W , 从而最大限度发挥算力;根据负载加速应用性能 , 支持RAS、ECC;通过硬件架构设计、硬件模块及软件全栈的配合 , 实现温度、电流、功耗等监测保护 , 可提供高能效比FP32算力和省电模式 。
3、设备虚拟化(MID):最大可支持4个设备实例 , 具备计算与存储资源的独享性 , 多用户间安全隔离;单颗芯片上可同时部署不同的业务与负载 , 实现多任务并行 , 有效提高利用率;支持KVM、Xen等系统虚拟化平台;性能开销不到物理机的3% 。
4、易编程、生态开放:开放C++和Python编程接口 , 支持CNN及NLP典型模型 , 支持TensorFlow、PyTorch、ONNX等主流机器学习框架 , 并通过SDK提供深度定制 。
目前云燧i10已支持来自浪潮、Supermicro、新华三的8款AI服务器 。 云端高算力密度推理服务器半精度算力可达1.1PFLOPS , 边缘云推理服务器半精度算力可达280TFLOPS 。
 文章插图
文章插图
当然 , 仅仅有高性能的硬件产品还不够 , 要充分挖掘硬件算力 , 必然离不开完善的软件工具 。
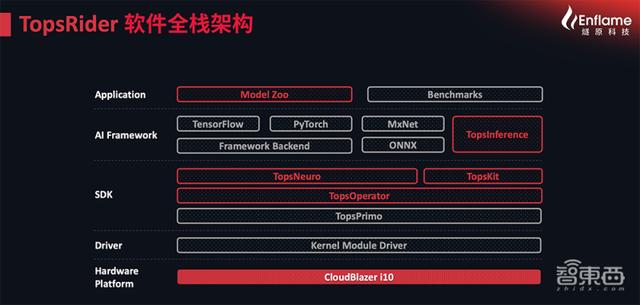
三、从无到有 , 打造推理软件全栈在研发云燧i10的同时 , 燧原从无到有地建立了一套对开发者友好的推理软件全栈 , 提供不同层次的开发模式 , 以及针对客户定制化算法模型的联合开发与优化 。
这一软件全栈在应用层、框架层、SDK层和驱动层这四个层面进行布局 。
 文章插图
文章插图
- 消防|阿里云AIoT云端一体重磅新品 国内首款安消一体机评测报告
- 研究人员吐槽当前AI训练效率过于低下
- Cloud PC服务曝光:将Windows 10桌面挪到云端
- 5G云游戏,云端存储有多爽?移动5G测评官当场试玩,体验大升级
- 研究人员吐槽当前的AI训练效率不高 浪费太多精力和能源
- 小度、天猫精灵、小爱同学挤占的智能音箱赛道:生死分明,寡头挺进
- Aruba全新解决方案助力转型,迈向边缘到云端的“多数据中心”
- 科技赋能惠民,山东邮政与顺能网络携手助力医养健康云端服务
- 各平台持续霸榜 realme挺进国内5G手机出货量TOP5
- 心率训练法科学指导 华为健跑沙龙北京站热情开跑