Redis集群做法的难点,百万并发客户端「实战」( 五 )
创建启动集群的启动脚本 , 内容如下:/redis-trib.rb create --replicas 1 192.168.25.128:7001 192.168.25.128:7002 192.168.25.128:7003 192.168.25.128:7004 192.168.25.128:7005 192.168.25.128:7006执行此脚本Creating clusterConnecting to node 192.168.25.128:7001: OKConnecting to node 192.168.25.128:7002: OKConnecting to node 192.168.25.128:7003: OKConnecting to node 192.168.25.128:7004: OKConnecting to node 192.168.25.128:7005: OKConnecting to node 192.168.25.128:7006: OKPerforming hash slots allocation on 6 nodes…Using 3 masters:192.168.25.128:7001192.168.25.128:7002192.168.25.128:7003Adding replica 192.168.25.128:7004 to 192.168.25.128:7001Adding replica 192.168.25.128:7005 to 192.168.25.128:7002Adding replica 192.168.25.128:7006 to 192.168.25.128:7003M: 2e48ae301e9c32b04a7d4d92e15e98e78de8c1f3 192.168.25.128:7001slots:0-5460 (5461 slots) masterM: 8cd93a9a943b4ef851af6a03edd699a6061ace01 192.168.25.128:7002slots:5461-10922 (5462 slots) masterM: 2935007902d83f20b1253d7f43dae32aab9744e6 192.168.25.128:7003slots:10923-16383 (5461 slots) masterS: 74f9d9706f848471583929fc8bbde3c8e99e211b 192.168.25.128:7004replicates 2e48ae301e9c32b04a7d4d92e15e98e78de8c1f3S: 42cc9e25ebb19dda92591364c1df4b3a518b795b 192.168.25.128:7005replicates 8cd93a9a943b4ef851af6a03edd699a6061ace01S: 8b1b11d509d29659c2831e7a9f6469c060dfcd39 192.168.25.128:7006replicates 2935007902d83f20b1253d7f43dae32aab9744e6Can I set the above configuration? (type ‘yes’ to accept): yesNodes configuration updated 。。。。。。。。。。 省略 。。。。。。 test it!注意:可能遇到到问题1、xxx is not Empty,请停着个xxx的节点 , 删除bin目录下的dump.rdb,notes.conf,note6380.conf,必要时删除/var/run/redis.pid2、cannot connect to xxxx , 你着redis配置密码了 , 在ruby的client里面写上你配置的密码 , 具体怎么找这个文件 , find命令3、执行集群启动基本一直卡在:Waiting for the cluster to join …,请在你服务器上开启16379和16380端口 , 反正就是10000+你redis的端口三、原理原理图如下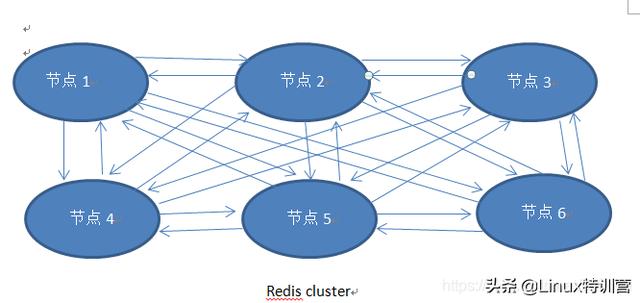 文章插图
文章插图eids cluster模式最小得6个服务 , 每个服务之间通过ping-pong机制实现相互感知(注意:此模式没有单独的哨兵监控 , 集群内部完全自制) 。 redis集群数据存储类似于hashmap , 其将数据划成16484个片区(又叫插槽 , 每个槽可以放n多个数据) , 通过对key进行一定的算法与16384取模 , 得到其在16384中间的一个片区中 。 如上图姑且认为1-4;2-5;3-6 , 两两结对 , 前者为master负责写(其实也具备读能力) , 后者slave负责读 , 而且是只读 , 防止数据出现不一致,同时slave从master同步数据 。 按照上述配对 , 1-4主从将只负责0-5500片区的读写;2~5主从只负责5501-11000片区的读写;3-6主从负责11001-16383片区的读写 , 从而实现了分摊了读写的压力 。
三、容灾恢复
- 主节点(如1)宕机 , 从节点(如4)将上位成master
- 主节点又活了 , 角色反转为slave
- 主从成对的宕机 , redis cluster将重新在剩下的节点上分配16384个片区(通过配置:cluster-require-full-coverage)
- 果粉有福了,苹果正式宣布新规,这个做法很库克
- 华为强行排除小米!而小米的做法却很亮眼!这次小米更有格局
- java 从零实现属于你的 redis 分布式锁
- HFL Redis_10_set类型底层存储数据结构
- 上海|全球科技集群100强发布,北京、上海、粤港三城跻身前十
- 为什么 Redis 单线程能支撑高并发?
- Redis流行的原因
- 摸方向盘就换挡、激光去污、磁悬浮雨刷,特斯拉尝试韭菜新做法
- 谁更有良心显而易见!关于手机屏幕,华为、OPPO做法差距明显
- C# Redis分布式锁 - 单节点