二叉状态树的结构,Part-1( 二 )
虽然还有很多棘手的细节有待深入 , 但要点看起来很清楚了:RLP 难以驯服 。 我们再来看看它是如何与状态树交织在一起的 。
默克尔化规则(Merkelization rule)我们怎么把 RLP 编码和它那令人厌烦的逻辑用到我们的默克尔化规则中?先从默克尔树底部的叶子节点开始说起 。
叶子节点及其十六进制前缀叶子节点保存了一个值(value) , 在这个值前面还有一个不知道多少位的键(key) , 这个键跟其它叶子节点的键肯定是不一样的 。 因此 , 我们有了一个元组
(key, value) , 这就是一个包含两个元素的列表 , 包含了key和value , 两个数据都是字节数组(byte array) 。 RLP 理论上应该能帮助我们编码这两个数据吧?不那么见得 。 一棵十六进制树上的 key 是基于半字节(nibble-based)的 , 所以如果我们取出一个键的时候 , 它可能在半字节处就中止了 , 那问题就来了:我该怎么对齐数据呢?这里面必须要有一个设计抉择 。 结果是 , 我们使用一种叫做 “十六进制前缀(hex prefix)方法” 的函数来读取键数据 , 它会加入一个 header 来告诉我们所读的键的长度究竟是偶数个还是奇数个半字节 。- 十六进制前缀编码方法使用第一个字节(即上文的 “头字节”)中的前半个字节来存储该键的长度(是奇数还偶数个半字节) 。 -
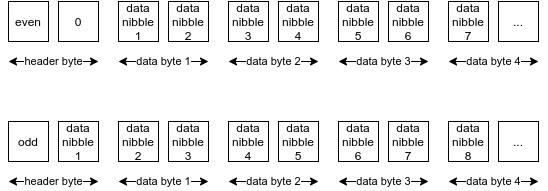
十六进制前缀方法还要求我们调整半字节的位置 。 举个例子 , 如果键的长度是奇数个半字节 , 那就把第一个半字节放到头字节的最后一个半字节的位置 。
 文章插图
文章插图同样地 , 如果长度是奇数 , 但跟字节的终止位置对不齐(not byte-aligned) , 那么每一个半字节都必须位移 , 以使其能以少一个字节的长度来存储 。
 文章插图
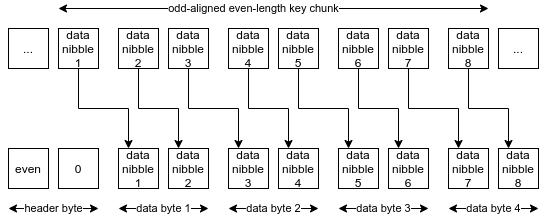
文章插图- 如果长度是偶数 , 但却是奇数对齐的(odd-aligned) , 那所有的半字节都要位移 4 个位 。 -所以 , 叶子节点最终是以
RLP(HP(key_chunk), value)的形式来编码的 。分支节点和太小的子节点一个分支节点(branch node)有 16 个子节点(childeren) , 每个字节点都占用半个字节 。 按照 RLP 的规则 , 分支节点只是一个其子节点哈希值的列表 , 也就是一个包含了 16 个字节数组的列表 。 如果某个子节点是空的 , 那就表示为一个空的数组(只是用一个独立的
128来标注一个长度为 0 的数组) 。 世界上 , 列表中还有第 17 个条目 , 就是分支节点本身的值 , 但因为实践中都不使用它 , 所以列表的最后一个条目总是128 。 没错 , 正如你所料 , 这里又会产生很多麻烦 。 为了避免在数据库中为太小的对象创建条目 , 一个 RLP 编码值太小的节点就不会计算出哈希值 。 在这种情况下 , 其 RLP 编码会直接存储为一个原始数据的列表 , 而不是这个列表的哈希值 。 结果就是你在列表中鲜少找到数组开始的标记(128) , 反而常常找到另一个列表开始的标记(192) , 又给开发者出了很多难题 。 如果一个分支节点的 RLP 的数据总大小大于 32 , 那它就会被算成哈希值 。 大部分时候都是如此 , 因为 , 如果没有算成哈希值 , 那就意味着一个子节点的 RLP 数据大小已达最大值:16 个字节 。延伸节点状态树上还有第三种节点 , 叫做延伸节点(extension node) , 我们放在下一篇文章中集中讨论 。 幸好 , 幸好 , 在 RLP 编码这一点上 , 它没有给我们增加任何麻烦 。
- “女性机器人”为啥火?外表颜值高、功能强,内部结构也一清二楚
- AMD Zen 3锐龙5000系列APU核心结构图曝光 较上一代更加强大
- 小米11官方公开内部结构,轻薄机身都藏了什么?
- 每经11点丨虾米音乐:2月5日起停止音乐服务;港股三大电信运营商直线拉升,均涨超5%;河北邢台全面进入战时状态
- 仅用168天,商汤科技“新一代人工智能计算与赋能平台”项目结构封顶
- 文化|广州再迎文化创意新地标!粤传媒大厦主体结构顺利封顶
- 每经22点 | 北京东城区:全区上下迅速进入应急状态;雷军回应小米“取消附送充电器”;国家卫健委医疗机构感染防控专家委员会成立
- 1184:平面点排序(二)&1185:添加记录(结构体专题)
- 工程项目|钢结构设计的发展前景?!国内分析...
- “停尸间已完全装满”,医疗系统进入紧急状态,苹果关闭加州所有零售店,医护人员控诉:我们已被压垮……