对话五位英伟达技术专家:解析GTC China大会不容错过的技术干货
 文章插图
文章插图
芯东西(公众号:aichip001)
作者 | 心缘
编辑 | 漠影
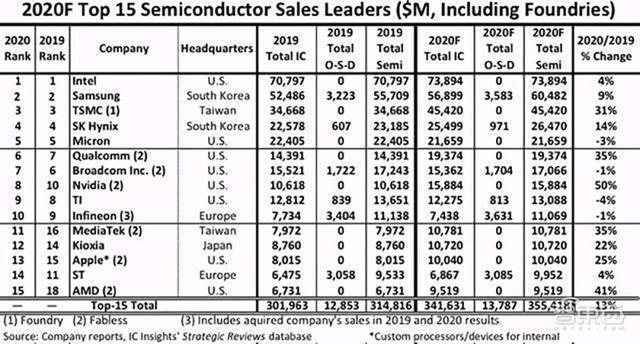
芯东西12月17日报道 , 根据知名行业调研机构IC Insights预测 , 2020年全球半导体销售额前十五大公司中 , NVIDIA(英伟达)增幅最大 , 有望较去年增长50% , 且排名比去年连升两位 。
 文章插图
文章插图
NVIDIA能取得如此显著的成绩 , 显然与今年的努力密不可分 。 在本周的NVIDIA GTC China线上大会期间 , 来自NVIDIA的五位中国技术专家与芯东西等媒体分享了NVIDIA在架构创新、数据中心平台、网络、图形渲染、嵌入式系统及自主机器等方面的进展及见解 。
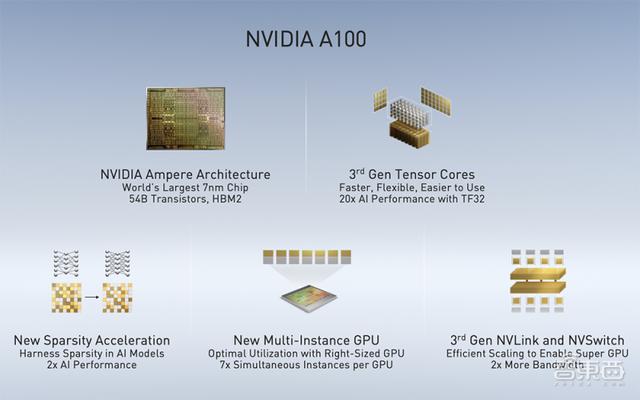
一、A100 GPU架构创新的三大特性今年5月 , NVIDIA在AI领域投下一颗惊雷——A100 GPU及系列计算产品横空问世 , 尤其是结构化稀疏模式下性能较上一代猛增 。
对此 , NVIDIA区中国工程和解决方案高级总监赖俊杰提到 , 之所以NVIDIA使GPU发展速度和性能提升呈现几倍、甚至几十倍的结果 , 更多依靠于架构方面的创新 。
 文章插图
文章插图
他重点强调了A100架构创新的三点特性:
第一点是第三代Tensor Core引入了TF32精度 , TF32精度介于FP 16和FP 32中间 , 在计算精度和速度之间取得了很好的折中 , 一方面有足够的动态范围和精度来保证神经网络训练时没有任何精度损失 , 另一方面能利用Tensor Core架构大大加速神经网络相关的一些计算性能 。
第二点是结构化稀疏 , 换种说法是对网络进行一些规律性的裁减 。 如果要借助神经网络稀疏性的特征 , 要想在实际硬件上取得可观的收益是非常难的 。 基于Ampere架构 , NVIDIA A100首次对稀疏性在架构上能够获得显著的提升 。 NVIDIA主要采用的一个逻辑 , 是对稀疏性做了一定的限制 , 每四个权重有两个为“0” , 通过这样的方式支持稀疏化计算的全新Tensor Core能够获得额外两倍的性能提升 。 根据实测 , 神经网络计算效果也能够得到1.5倍端到端的性能提升 。
第三点是多实例GPU , 允许对像A100这样比较大的GPU进行灵活的切分 , 这些切分成的GPU实例在硬件资源上实际上是隔离的 , 这就能够保证在这些不同的实例上互不影响地运行不同的应用 。
赖俊杰还介绍了提供GPU之间高速互连的第三代NVLink和NVSwitch , NVLink是GPU之间“点对点”高速互连 , NVSwitch在中间提供一个交换的结构 。 利用A100 GPU NVSwitch以及Mellanox高速网卡 , NVIDIA设计了DGX A100服务器 。 DGX A100服务器中有8块A100 GPU , 通过6个NVSwitch芯片完成高速互连 。
结合DGX服务器、Mellanox交换机和网络 , NVIDIA还可以搭建更大的数据中心规模解决方案或者参考架构 。 这是整个数据中心非常重要的一环 , 使得客户可以在非常短的时间就完成整个数据中心的搭建和部署 。
另外 , NVIDIA就整个软件生态环境在DGX、DGX POD以及DGX SuperPOD上的运行做了很多工作 , 能够确保这些软件的顺利运行 。
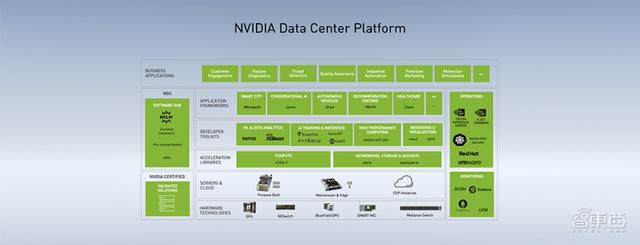
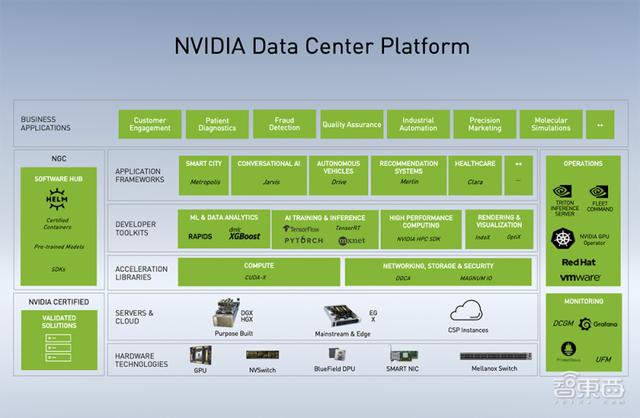
二、NVIDIA数据中心平台全景图NVIDIA GPU计算专家团队亚太区总监李曦鹏着重介绍了NVIDIA在数据中心建站方面的布局 。
 文章插图
文章插图
如图是NVIDIA数据中心平台图 , 从下到上依次是硬件、服务器和云、加速库、开发软件套件、应用框架、商业应用 。
李曦鹏说 , 中小企业、创业公司或传统企业 , 通过NVIDIA提供的硬件、软件及应用框架 , 配合1-2个工程师 , 就能得到不错的对话机器人、语音识别等系统 , 真正做到普惠 。
- 良心!英伟达461.09版驱动发布 修复GTX750Ti蓝屏
- 对话今年爆火的外骨骼机器人创始人,从民房起步连续创业的追梦者
- 喵博士资讯 | 中国手机在印度销量不降反升;英伟达正规划5nm架构显卡
- SolarWinds入侵事件余波:英特尔、英伟达、思科等科技巨头亦躺枪
- 挺进云端AI训练&推理双赛道!独家对话燧原科技COO张亚林:揭秘超高效率背后的“内功”
- 对话Graphcore中国高管:新IPU性能大幅超NV A100,中短期内冲市场第二
- 对话惠普范子军:立足用户需求 助力年轻人实现自我价值
- 中马青年以“数据新时代,携手创未来”为主题举行云端对话
- 英伟达正式发布RTX A6000工作站显卡:GA102完整核心 48GB大显存
- 英伟达考虑在中国建立研发中心 取决于人才招募进度