AMD Zen3架构深度解析!揭开性能暴涨39%的秘密
AMD基于Zen3全新架构的锐龙5000系列终于解禁上市了 , 不知道锐龙9 5950X、锐龙9 5900X的性能是否让大家满意?大喊YES的同时有没有剁手买买买?
接下来 , 快科技还会奉上锐龙7 5800X、锐龙5 5600X的评测 , 敬请期待 。
这次 , 锐龙一直以来可以说唯一弱势的单核心/游戏性能终于不再是短板 , 一举实现了对Intel的反超 , 而且还是在制造工艺维持7nm工艺完全不变的前提下做到的 , 全新设计的Zen3架构可以说功不可没 , 这也是Zen诞生以来最大规模的变革 。
 文章插图
文章插图
今天 , 我们就好好聊一聊Zen3架构的革新之处 。
当然了 , 处理器架构设计是极为高深的学问 , 我们不可能讲得多么深入、专业 , 就说说一些比较表层和便于理解的东西 , 看看如此逆天的性能飞跃究竟如何而来 。
 文章插图
文章插图
首先 , 做任何事都要有目标 , 设计一个处理器架构更是如此 。 Zen3的目标就有三个:
一是提升单线程性能 , 专业名词叫IPC(每时钟周期指令数) , 毕竟之前几代一直追求多核心为主 , 是时候把单核性能提升到足够的高度了 , 不然始终是瘸着脚走路 , 缺乏长久竞争力 。
二是在维持8核心CCD模块的前提下 , 统一核心与缓存 , 提升彼此通信效率 , 降低延迟 。
三是继续提高能效比 , 性能提升的同时功耗不能失控 。
 文章插图
文章插图
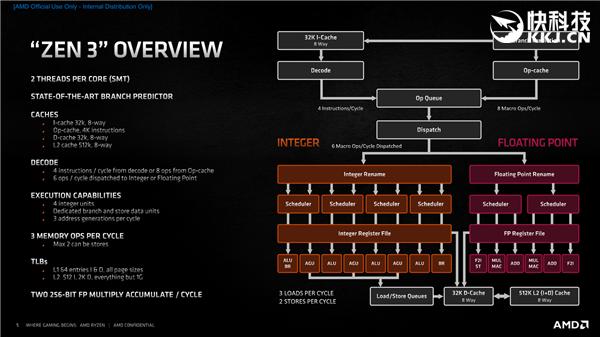
为此 , Zen3架构对于所有模块都进行了翻新 , 前端、预取、解码、执行、整数、浮点、载入、存储、缓存等等 , 每个环节都是焕然一新 。
首先 , Zen3设计了一个堪称艺术级的分支预测器 , 它之后有两条通道将指令送入队列 , 然后进行分派 , 一是8路关联的32KB一级指令缓存和x86解码器 , 二是4K指令的操作缓存(Op-cache) 。
x86解码器的限制是每个时钟周期只能处理最多4条指令 , 但如果是熟悉的指令 , 就可以放入操作缓存 , 每个周期就能处理8条 , 二者结合指令分发效率就大大提升 , 相比于Zen2直接上升了一个档次 。
指令分派之后就来到执行引擎阶段 , 分为整数、浮点两大部分 , 每个时钟周期可以向它们分派6条指令 。
其中 , 整数单元还是4个 , 但更加分散 , 并增加了一个单独的分支与数据存储单元 , 提升吞吐量 , 每时钟周期可以生成3个地址 。
浮点方面则分为六条流水线 , 进一步提升吞吐量和效率 。
内存方面 , 每时钟周期可以执行3个载入 , 或者1个载入加2个存储 , 再次提升吞吐量 , 并且可以更灵活地处理不同工作负载 。
 文章插图
文章插图
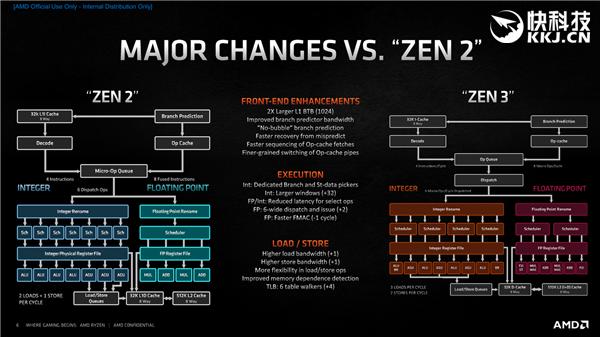
单纯说Zen3可能感觉不到什么 , 那就对比一下Zen2 , 变化太多还是捡最核心的说 。
前端方面 , 主要有容量翻番的L1 BTB、更大的分支预测器带宽、更快的预测错误恢复、更快的操作缓存拾取、更精细的操作缓存流水线切换 , 等等 。
执行引擎方面 , 主要有独立的分支与数据存储单元、更大的整数窗口、更低的特定整数/浮点指令延迟、6宽度拾取与分发、更宽的浮点分派、更快的浮点FMAC(乘法累加器) , 等等 。
载入/存储方面 , 主要有更高的载入带宽(2个变3个)、更高的存储带宽(1个变2个)、更灵活的载入/存储指令、更好的内存依赖检测 , 等等 。
 文章插图
文章插图
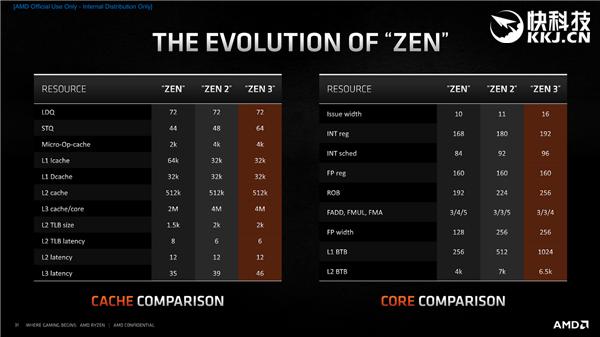
以上是Zen、Zen2、Zen3三代架构在核心、缓存一些关键指标上的变化 。 乍一看 , Zen3变化的力度似乎不如Zen2 , 但一则这些数字不能完全反应更深层次的变化 , 二则Zen3在关键指标上更有突破 , 比如说分发宽度从10/11一跃来到16 , 执行效率提升可不止一点半点 。
- AMD Zen3 APU内核图提前偷跑:三级缓存质变
- AMDCES发布会1月13日凌晨0点开始:苏姿丰作主题演讲
- AMD官宣CEO苏姿丰CES演讲:锐龙5000笔记本打头阵
- Zen3发飙!锐龙7 5800U跑分流出:多核暴涨27%
- 8核Zen3 AMD新CPU现身:锐龙7 5700G
- AMD Zen 3锐龙5000系列APU核心结构图曝光 较上一代更加强大
- AMD 专利展现 MCM 模块化芯片设计,GPU 将采用多核封装
- NVIDIA 5nm架构猛料:流处理器超1.84万个
- AMD、Apple、ARM围堵下,intel的“离婚冷静期”冷得刺骨
- 5nm Zen4来了!AMD 15年来首超Intel 这逆袭太猛