有关自然语言处理的深度学习知识有哪些?( 六 )
大家再来想象一下 , 如果将一个感知机作为第二个感知机的输入 , 是不是更令人困惑了 , 这到底是在做什么?
反向传播可以解决这个问题 , 但首先需要稍微调整一下感知机 。 记住 , 权重是根据它们对整体误差的贡献来更新的 。 但是如果权重对应的输出成为另一个感知机的输入 , 那么从第二个感知机开始 , 我们对误差的认识就变得有些模糊了 。
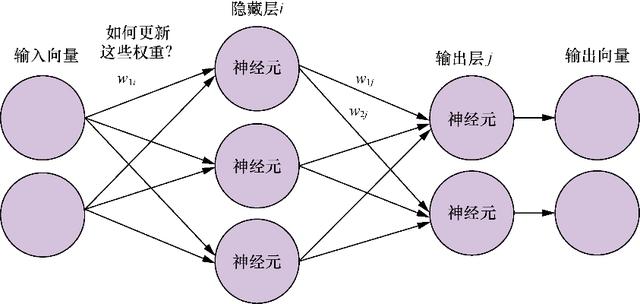
如图5-6所示 , 权重w1i通过下一层的权重(w1j)和(w2j)来影响误差 , 因此我们需要一种方法来计算w1i对误差的贡献 , 这个方法就是反向传播 。
 文章插图
文章插图
图5-6 包含隐藏权重的神经网络
现在是时候停止使用“感知机”这个术语了 , 因为之后大家将改变每个神经元权重的更新方式 。 从这里开始 , 我们提到的神经元将更通用也更强大 , 它包含了感知机 。 在很多文献中神经元也被称为单元或节点 , 在大多数情况下 , 这些术语是可以互换的 。
所有类型的神经网络都是由一组神经元和神经元之间的连接组成的 。 我们经常把它们组织成层级结构 , 不过这不是必需的 。 如果在神经网络的结构中 , 将一个神经元的输出作为另一个神经元的输入 , 就意味着出现了隐藏神经元或者隐藏层 , 而不再只是单纯的输入层、输出层 。
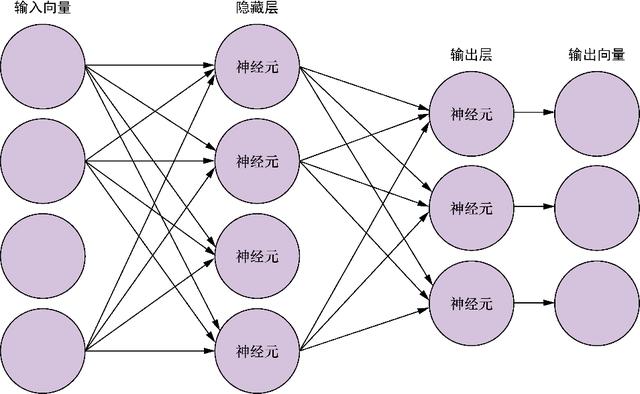
图5-7中展示的是一个全连接网络 , 图中没有展示出所有的连接 , 在全连接网络中 , 每个输入元素都与下一层的各个神经元相连 , 每个连接都有相应的权重 。 因此 , 在一个以四维向量为输入、有5个神经元的全连接神经网络中 , 一共有20个权重(5个神经元各连接4个权重) 。
感知机的每个输入都有一个权重 , 第二层神经元的权重不是分配给原始输入的 , 而是分配给来自第一层的各个输出 。 从这里我们可以看到计算第一层权重对总体误差的影响的难度 。 第一层权重对误差的影响并不是只来自某个单独权重 , 而是通过下一层中每个神经元的权重来产生的 。 虽然反向传播算法本身的推导和数学细节非常有趣 , 但超出了本书的范围 , 我们对此只做一个简单的概述 , 使大家不至于对神经网络这个黑盒一无所知 。
反向传播是误差反向传播的缩写 , 描述了如何根据输入、输出和期望值来更新权重 。 传播 , 或者说前向传播 , 是指输入数据通过网络“向前”流动 , 并以此计算出输入对应的输出 。 要进行反向传播 , 首先需要将感知机的激活函数更改为稍微复杂一点儿的函数 。
 文章插图
文章插图
图5-7 全连接神经网络
到目前为止 , 大家一直在使用阶跃函数作为人工神经元的激活函数 。 但是接下来会发现 , 反向传播需要一个非线性连续可微的激活函数[11] , 如公式5-4中常用的sigmoid函数所示 , 现在每个神经元都会输出介于两个值(如0和1)之间的值:
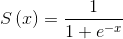 文章插图
文章插图
公式5-4 sigmoid函数
为什么激活函数需是非线性的
因为需要让神经元能够模拟特征向量和目标变量之间的非线性关系 。 如果神经元只是将输入与权重相乘然后做加和 , 那么输出必然是输入的线性函数 , 这个模型连最简单的非线性关系都无法表示 。
之前使用的神经元阈值函数是一个非线性阶跃函数 。 所以理论上只要有足够多的神经元就可以用来训练非线性关系模型 。
这就是非线性激活函数的优势 , 它使神经网络可以建立非线性关系模型 。 一个连续可微的非线性函数 , 如sigmoid , 可以将误差平滑地反向传播到多层神经元上 , 从而加速训练进程 。 sigmoid神经元的学习速度很快 。
- RHEL 9提升了x86_64处理器的入门要求
- 联想IdeaPad 5 Pro系列笔记本发布 可选两种处理器和两种尺寸
- 联想推出搭载骁龙处理器的IdeaPad 5G
- 性能翻倍!飞腾首款8核桌面处理器腾锐D2000详解
- 苹果自研新处理器曝光:64核心
- 推进|我国今年将推进快递“进村”“进厂”“出海”构建日处理超10亿件寄递网络
- 支付处理公司Juspay发生数据泄漏:1亿用户信息在暗网出售
- NVIDIA 5nm架构猛料:流处理器超1.84万个
- 虾米音乐宣布关停:今日停止会员充值,开启个人资料处理通道
- 除了 Markdown 编辑器,你还需要会用程序来处理它