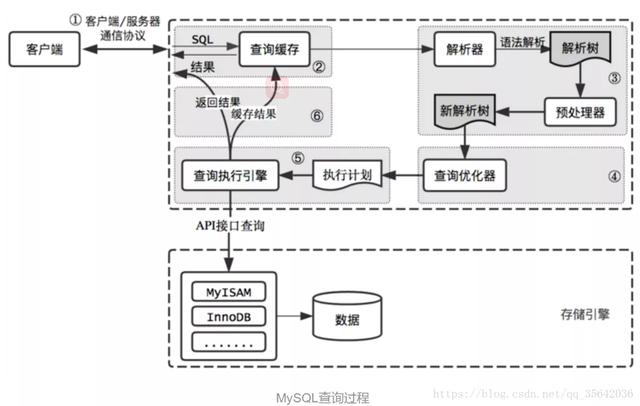
实践中如何优化MySQL(建议收藏!)
- SQL语句的优化:
- 1、尽量避免使用子查询
- 3、用IN来替换OR
- 4、LIKE前缀%号、双百分号、_下划线查询非索引列或*无法使用到索引 , 如果查询的是索引列则可以
- 5、读取适当的记录LIMIT M,N , 而不要读多余的记录
- 6、避免数据类型不一致
- 7、分组统计可以禁止排序sort , 总和查询可以禁止排重用union all
- 8、避免随机取记录
- 9、禁止不必要的ORDER BY排序
- 10、批量INSERT插入
- 11、不要使用NOT等负向查询条件
- 12、尽量不用select *
- 13、**区分in和exists**
- 索引的优化:
- 1、Join语句的优化
- 2、避免索引失效
 文章插图
文章插图① SQL语句及索引的优化SQL语句的优化:1、尽量避免使用子查询
 文章插图
文章插图2、避免函数索引
 文章插图
文章插图3、用IN来替换OR
 文章插图
文章插图另外 , MySQL对于IN做了相应的优化 , 即将IN中的常量全部存储在一个数组里面 , 而且这个数组是排好序的 。 但是如果数值较多 , 产生的消耗也是比较大的 。 再例如:select id from table_name where num in(1,2,3) 对于连续的数值 , 能用 between 就不要用 in 了;再或者使用连接来替换 。
4、LIKE前缀%号、双百分号、_下划线查询非索引列或*无法使用到索引 , 如果查询的是索引列则可以
 文章插图
文章插图5、读取适当的记录LIMIT M,N , 而不要读多余的记录
select id,name from table_name limit 866613, 20使用上述sql语句做分页的时候 , 可能有人会发现 , 随着表数据量的增加 , 直接使用limit分页查询会越来越慢 。优化的方法如下:可以取前一页的最大行数的id , 然后根据这个最大的id来限制下一页的起点 。 比如此列中 , 上一页最大的id是866612 。 sql可以采用如下的写法:
select id,name from table_name where id> 866612 limit 206、避免数据类型不一致7、分组统计可以禁止排序sort , 总和查询可以禁止排重用union all 文章插图
文章插图union和union all的差异主要是前者需要将结果集合并后再进行唯一性过滤操作 , 这就会涉及到排序 , 增加大量的CPU运算 , 加大资源消耗及延迟 。 **当然 , union all的前提条件是两个结果集没有重复数据 。 **所以一般是我们明确知道不会出现重复数据的时候才建议使用 union all 提高速度 。
另外 , 如果排序字段没有用到索引 , 就尽量少排序;
8、避免随机取记录
 文章插图
文章插图9、禁止不必要的ORDER BY排序
 文章插图
文章插图10、批量INSERT插入
 文章插图
文章插图11、不要使用NOT等负向查询条件你可以想象一下 , 对于一棵B+树 , 根节点是40 , 如果你的条件是等于20 , 就去左面查 , 你的条件等于50 , 就去右面查 , 但是你的条件是不等于66 , 索引应该咋办?还不是遍历一遍才知道 。
- 红米K40渲染图曝光:居中挖孔+后置四摄,这外观你觉得如何?
- 视网膜优化?索尼具认知能力电视芯片XR来了
- 奋斗|该如何看待拼多多员工猝死:鼓励奋斗,也要保护好奋斗者
- 装机点不亮 如何简易排查硬件问题?
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 人脸识别设备主板如何选型 软硬整合大幅缩短开发时间
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能
- Mini-LED产品效果究竟如何?
- 专家介绍如何判断智能手机被入侵:运行速度变慢、电池消耗过快以及卡顿
- 最便宜的骁龙888手机?红米K40曝光:这外观如何?