大神使用Python爬取微信群里的百度云资源( 三 )
可以看到这两行
yunData.SHARE_ID = "3927175953";yunData.SHARE_UK = "140959320"; // 经过对比 , 这就是我们要的 "from"yunData.PATH 只指向了一个路径信息 , 完整的filelist 可以从yunData.FILEINFO里提取 , 它是一个json, list里的信息是Unicode编码的 , 所以在控制台看不到中文 , 用Python代码访问并获取输出一下就可以了 。
直接用request请求会收获404 错误 , 可能是需要构造请求头参数 , 不能直接请求 , 这里博主为了节省时间 , 直接用selenium的webdriver来get了两次 , 就收到了返回信息 。 第一次get没有任何 cookie, 但是baidu 会给你返回一个BAIDUID, 在第二次get 就可以正常访问了 。
yunData.FILEINFO 结构如下 , 你可以将它复制粘贴到json.cn里 , 可以看得更清晰 。
[{"fs_id":3097042711872,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"归来的福丹芝(58)","size":0,"server_mtime":1502150215,"server_ctime":1494903797,"local_mtime":1494903797,"local_ctime":1494903797,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"4215521821664681584","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/我的资源\/归来的福丹芝(58)","root_ns":1653016720,"md5":"","file_key":""},{"fs_id":1057404338934434,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"多样的儿媳(46)","size":0,"server_mtime":1502150223,"server_ctime":1496696760,"local_mtime":1496696760,"local_ctime":1496696760,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"5972282562760833248","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/我的资源\/多样的儿媳(46)","root_ns":1653016720,"md5":"","file_key":""}]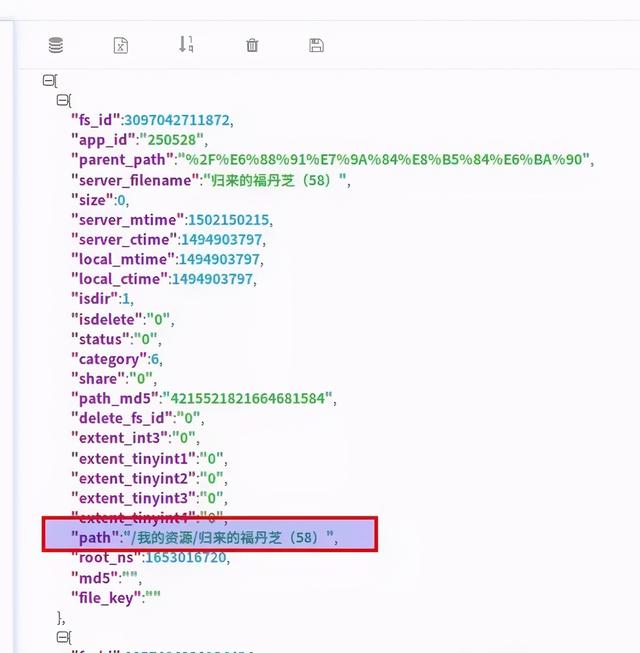 文章插图
文章插图
清楚了这三个参数的位置 , 我们就可以用正则表达式进行提取了 。 代码如下:
from wechat_robot.business import proxy_mine # 这是我自己的代理类 , 测试时可以先用本机ip?pro = proxy_mine.Proxy()url = "/s/1jImSOXg"driver = webdriver.Chrome()print u"初始化代理..."driver = pro.give_proxy_driver(driver)?def get_file_info(url):driver.get(url)time.sleep(1)driver.get(url)?script_list = driver.find_elements_by_xpath("//body/script")innerHTML = script_list[-1].get_attribute("innerHTML")# 获取最后一个script的innerHTML?pattern = 'yunData.SHARE_ID = "(.*?)"[\s\S]*yunData.SHARE_UK = "(.*?)"[\s\S]*yunData.FILEINFO = (.*?);[\s\S]*'# [\s\S]*可以匹配包括换行的所有字符,\s表示空格 , \S表示非空格字符srch_ob = re.search(pattern, innerHTML)?share_id = srch_ob.group(1)share_uk = srch_ob.group(2)?file_info_jsls = json.loads(srch_ob.group(3))# 解析jsonpath_list = []for file_info in file_info_jsls:path_list.append(file_info['path'])?return share_id,share_uk,path_list?try:print u"发送连接请求..."share_id,share_uk,path_list = get_file_info(url)except:print u"链接失效了 , 没有获取到fileinfo..."else:print share_idprint share_ukprint path_list爬取到了这三个参数 , 就可以调用之前的transfer方法进行转存了 。
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 或使用天玑1000+芯片?荣耀V40已全渠道开启预约
- 苹果将推出使用mini LED屏的iPad Pro
- 手机能用多久?如果出现这3种征兆,说明“默认使用时间”已到
- 苹果有望在2021年初发布首款使用mini LED显示屏的 iPad Pro
- 笔记本保养有妙招!学会这几招笔记本再战三年
- 2021年Java和Python的应用趋势会有什么变化?
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 数据可视化三节课之二:可视化的使用