当数据库遇上"自动驾驶",阿里云 DAS 在自治诊断的突破( 三 )
Large-scale
从集团到阿里云 , 我们管控的实例数从几万到超过50万实例 , 我们对离线计算链路与实时计算链路有巨大的挑战 , 这里我们把算法部署到我们DASMind算法服务 , 底层借助与函数计算的弹性扩展能力 , 最大程度的节省资源和保障我们流计算的稳定性 。
Multiple Database Engines
我们目前已经支持MySQL/PolarDB 等关系型数据库 , 也要支持Redis/Mongo 等NoSQL数据库 , 我们希望通过一个具有鲁棒性的方式 , 来沉淀DBA的经验 , 而不是针对每一个数据库单独设计一套规则式的根因定位方法 , 尽可能的降低我们跨引擎标注case沉淀经验的成本 。
 文章插图
文章插图
方案
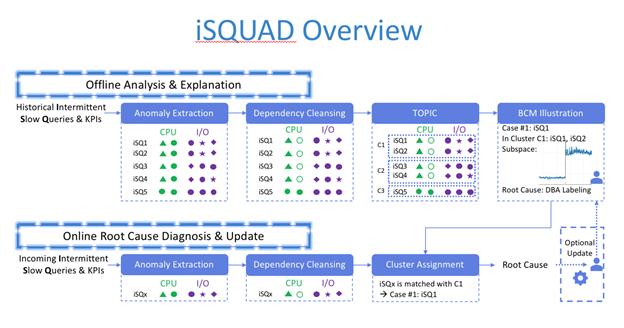
iSQUAD Overview
我们设计了iSQUAD这套框架并嵌入到DAS算法服务DASMind当中 , 方案分为离线和在线两条链路 。
离线:通过对历史iSQ数据的探测 , 来触发异常抽取模块 , 抽取异常的特征 , 在通过过滤重复指标 , 将每个iSQ对应的pattern进行聚类 , 获得丰富的cluster , 这些cluster通过BCM模块的特征子空间的抽取后 , 用来给DBA进行标注 , 标注的样本沉淀出pattern的模型 , 并提供给在线实时根因定位模块做分析 , 这样在线链路从之前了1-5-10(1分钟发现异常 , 5分钟定位分类 , 10分钟发出action)的方式得到了升级 , 我们把异常发现和根因定位分类这6分钟时间压缩到了1分钟以内 , 做到了实时根因定位 。
 文章插图
文章插图
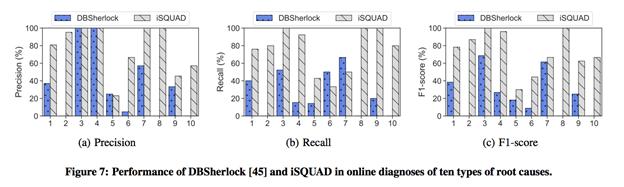
对于整体iSQAUD的在线诊断效果 , 我们对比了SIGMOD 2016 Dbsherlock: A performancediagnostic tool for transactional databases 。
 文章插图
文章插图
本方案系统图 , 分为4个模块:
1) 异常检测模块(Anomaly Extract):
 文章插图
文章插图
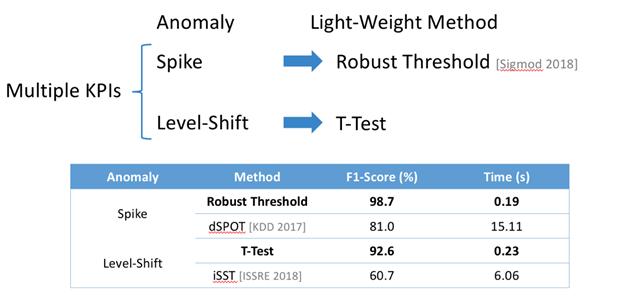
通过对多指标时序序列异常检测 , 通过 Robust Threshold 鲁棒性的阈值预测方法 , 结合时序序列周期性的方法 , 生成动态阈值 , 来判定每个指标的上限边界 , 并解析出相应特征是否为spike/meanshift/,此方法对比T-Test等传统方法对更加实用和快速的判断指标波动方向 , 下图与传统T-Test方法对比:
 文章插图
文章插图
 文章插图
文章插图
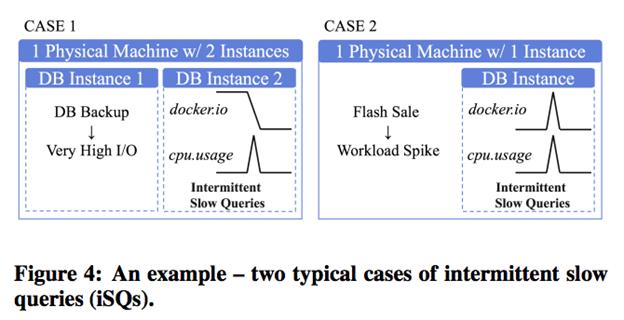
在实际业务场景中 Robust Threshold , 对于稳定的时序序列可以很好检测出spike/meanshift 特征 , 但是业务场景往往是复杂的 , 对于Additive Model/Multiplicative Model/Weak-Seasonality, 我们DAS产品采用更加丰富异常检测算法库去识别多个不同的时序特征 , 关于异常检测的方法将在后续文章详细展开 。 本paper着重对spike和meanshift特征进行了检测 。
2) 关联分析, 指标依赖关系过滤模块(Dependencies cleaning):
 文章插图
文章插图
多指标存在依赖 , 通过大量历史数据关联分析 , 把异常方向总是波动相同的指标清理掉 , 留下关键指标 , 对比DBA经常关注的指标 , 有一定的相似性通过A异常/B异常的关联性推导出 , AB两个指标是否关联 , 此类关联分析方法用很多 , 并未对此方法单独和传统方法作对比:
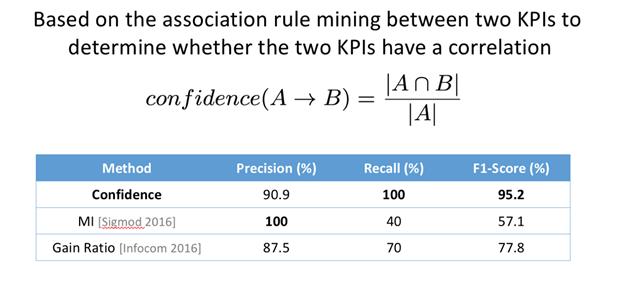 文章插图
文章插图
- 雷军再次放大招,小米"轻装上阵"后,华为还能扛得住吗?
- 美国公司破解"刷脸支付"?用马云照片做实验,结果弹出4个大字
- 苹果改变立场 称macOS实用程序Amphetamine可继续留在Mac应用商店中
- "二八定律"难破 CPU市占率英特尔持续占优
- 用了两到三年的华为手机,一键打开"开发者选项",帮助性能加速
- AMP Robotics募资5500万美元 开发AI对可回收物进行分拣
- 4575万高像素&4K高画质 尼康Z7值得选
- 毫无敬畏之心!南京大屠杀遇难同胞纪念馆被标"休闲娱乐好去处",美团:立即改正
- 5G,真的"扶不起"吗?
- EMUI11升级适配最新进展!涉及华为&荣耀37款机型