R数据分析:资料缺失值的常见处理方法
在数据预处理时 , 一个常见的问题就是缺失值的处理 , 今天再写一次缺失值处理 。
在R中缺失值会被表现为NA(not available) , 我们可以使用is.na()函数来查看我们的资料中是否有缺失值:
tmp <- c(1,5,8,NA,5,NA,6)is.na(tmp)[1] FALSE FALSE FALSETRUE FALSETRUE FALSE还可以计算缺失的个数:
【R数据分析:资料缺失值的常见处理方法】sum(is.na(tmp))2在处理缺失值的过程中很多人会选择“直接删除缺失值”或者“使用平均值插补缺失” , 这两个方法都是有一定问题的 , 前者会让资料减少 , 后者也不会增加新的信息相当于没有处理 。
比较推崇的处理缺失值的方法一个是用「k-Nearest Neighbours」 , 另外就是用「mice」进行多重插补 。 这两个方法其实都不难 , 我们看看具体怎么做:
require(missForest)#在iris中随机产生0.1的缺失值data <- prodNA(iris, noNA = 0.1)head(data)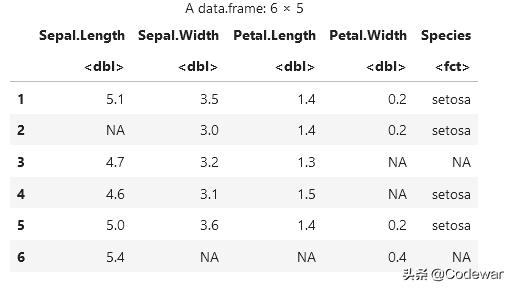 文章插图
文章插图
直接删除缺失值# 使用如下函数 , 没有缺失就会返回T,有的话返回Fcomplete.cases(data) 文章插图
文章插图
#直接删除所有的缺失值rm.data <- data[complete.cases(data), ]用均数插补# 用均数插补mean.data <- datamean.1 <- mean(mean.data[, 1], na.rm = T)# 第一列的均数na.rows <- is.na(mean.data[, 1])# 第一列的缺失值的行# 用第一列的均数插补缺失列mean.data[na.rows, 1] <- mean.1用K-Nearest Neighbours插补先简单介绍一下KNN原理:
比如我们现在有一个班的学生的成绩 , 包括语文、数学、英语 , 然后小明同学的英语成绩有缺失 , 我们用knn的思想就是:我们看小明的语文、数学成绩 , 看他这两门成绩和哪些同学的成绩比较接近 , 然后我们再用这接近的(K位)同学的英语成绩取平均作为小明的英语成绩 。
一句话概括:就是给缺失的单位找K个最相近的邻居 , 然后用这些个邻居的值代替缺失的值 。
require(DMwR)#要用这个包imputeData <- knnImputation(data)head(imputeData)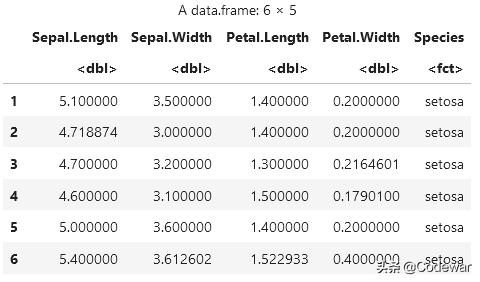 文章插图
文章插图
用mice填补缺失值很多时候我们还能利用数据集的现有信息对缺失数据进行预测 , 这样一种方法就最大化利用了数据集的现有信息 。
比如:我们有V1,V2,V3……Vn这些个变量 , 每一个变量都有缺失值 , 当我们想要插补V1的缺失值时 , 我们就用V2,V3……Vn作为自变量 , V1作为应变量进行建模预测V1的缺失 。
同理 , 针对V2的缺失 , 就用V1,V3……Vn建模 。
require(mice)mice.data <- mice(data,m = 3,# 插补3个完整数据集maxit = 50,# max iterationmethod = "cart", # 使用CART决策数进行预测seed = 188)# set.seed() , 令每次抽样都一样# 原始数据data# 插补好的资料 , 因为我们的m=3所以有3个完整的数据集 , 可以用以下方式取出complete(mice.data, 1) # 1st datacomplete(mice.data, 2) # 2nd datacomplete(mice.data, 3) # 3rd data总结感谢大家耐心看完 。 发表这些东西的主要目的就是督促自己 , 希望大家关注评论指出不足 , 一起进步 。 内容我都会写的很细 , 用到的数据集也会在原文中给出链接 , 你只要按照文章中的代码自己也可以做出一样的结果 , 一个目的就是零基础也能懂 , 因为自己就是什么基础没有从零学Python和R的 , 加油 。
(站外链接发不了 , 请关注后私信回复“数据链接”获取本头条号所有使用数据)
- 虾米音乐宣布关停:今日停止会员充值,开启个人资料处理通道
- 数据分析与机器学习:侦测应用内机器人作弊关键
- 资料|让R取代SPSS,想发低分SCI都难
- 女子去维修手机,手机中的私密资料被看到,对方:你的第一个知道的
- 还在当社畜?不如自学python改变现状 最全的资料都在这里
- 买大屏智能投影 这几个功能不能缺失
- 差距!关于华为新机,iPhone12的“良心”在华为身上缺失
- 这个区在全市率先实现区属医疗机构医生工作站上影像资料的跨区调阅,探索“互联网+健康管理模式”
- 苹果iPhone 13将提升续航 还将弥补一项最大缺失
- 我把大学四年的Java私藏资料都贡献出来了,等你来领