华为云FusionInsight湖仓一体解决方案的来世今生
伴随5G、大数据、AI、IoT的飞速发展,数据呈现大规模、多样性的极速增长,为了应对多变的业务诉求,政企客户对数据处理分析的实时性和融合性提出了更高的要求,“湖仓一体”的概念应运而生,它打破数据湖与数仓间的壁垒,使得割裂数据融合统一,减少数据分析中的搬迁,实现统一的数据管理 。
早在2020年5月份的华为全球分析师大会上,华为云CTO张宇昕提出了“湖仓一体”概念,在随后的华为云与计算城市峰会上,“湖仓一体”理念跟随华为云FusionInsight智能数据湖在南京、深圳、西安、重庆等地均有呈现,在刚结束的HC2020上,张宇昕在发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念 。 那我们就来看看湖仓一体的来世今生 。
数据湖和数据仓库的发展历程和挑战
早在1990年,比尔·恩门(Bill Inmon)提出了数据仓库,主要是将组织内信息系统联机事务处理(OLTP)常年累积的大量资料,按数据仓库特有的资料储存架构进行联机分析处理(OLAP)、数据挖掘(Data Mining)等分析,帮助决策者快速有效地从大量资料中分析出有价值的资讯,以利决策制定及快速响应外在环境变化,帮助构建商业智能(BI) 。
大约十年前,企业开始构建数据湖来应对大数据时代,它通常把所有的企业数据统一存储,既包括源系统中的原始副本,也包括转换后的数据,比如那些用于报表, 可视化, 数据分析和机器学习的数据 。
纵观数据湖与数据仓库的技术发展,不难发现两者有着各自的优劣,具体表现如下:
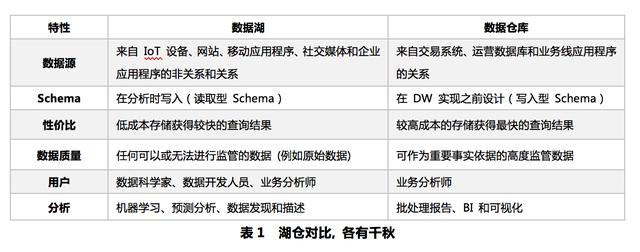 文章插图
文章插图
企业在进行系统架构设计选型时,需要从具体的分析场景出发,单一的模式已经无法满足企业发展的业务诉求,集中表现在以下两个痛点:
?数据湖主要以离线批量计算为主,因为不支持数据仓库的数据管理能力,难以提高数据质量;数据入湖时效差不支持实时更新,数据无法强一致性;主题建模不友好,无法直接历史拉链建模;同时交互分析通常将数据搬迁到数据仓库平台,造成分析链路长,数据冗余存储;批同时仓缺乏全局数据视图,不同平台接口差异和不同开发管理工具,造成用户开发使用复杂,数据分别管理维护代价高体验差 。
数据湖和数据仓库正在从两条技术演进路线走向融合
综上,数据湖和数据仓库在企业数据分析场景分别承担一湖一仓的重要角色,形成了完整的数据分析生态系统,上述企业场景面临的2个关键痛点也在驱动数据湖和数据仓库在技术演进上走向融合:
第一个融合方向是基于Hadoop体系的数据湖向数据仓库能力扩展,湖中建仓,从DataLake进化到LakeHouse 。 LakeHouse结合了数据湖和数据仓库特点,直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能 。 目前业界已经涌现了一些LakeHouse产品,如NexFlix开源Iceberg、Uber开源Hudi、Databricks的 DeltaLake 。
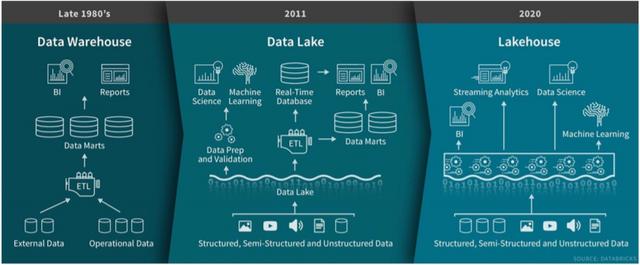 文章插图
文章插图
【华为云FusionInsight湖仓一体解决方案的来世今生】图2从DataLake进化到LakeHouse,数据湖扩展数仓能力
以目前生态发展迅速的Apache Hudi为例:统一数据存储,分布式存储不同应用所需的各种类型数据;数仓模式执行和治理,实现事务支持各种分析引擎,统一数据存储通过开放和标准化的存储格式(如Parquet),提供API以便各类工具和引擎(包括机器学习和Python / R库)直接有效地访问数据 。
虽然LakeHouse并不能完全替代数据仓库,但通过增强性能,支持实时入湖、建模、交互分析等场景,将在企业分析环境中发挥更大作用 。
第二个融合方向是数据湖和数据仓库协同起来向湖仓一体的融合分析架构发展,随着企业数据量快速增长,不仅是结构化数据,也有非结构化数据,同时提出了对搜索/机器学习更多的能力要求,使得原来数仓技术不能够有效的处理复杂场景,为此需扩展原有系统,引入Hadoop大数据平台实现新类型数据、新业务场景的支持 。 在这个背景下由Gartner在2011年提出逻辑数据仓库的概念,预测企业数据分析倾向于转向一种更加逻辑化的架构,利用分布式处理、数据虚拟化以及元数据管理等技术,实现逻辑统一物理分开的协同体系 。
- 华为P50 Pro亮点提前看:屏占比、颜值双双提升
- 5G手机好评榜,华为Mate40Pro无缘上榜,第一出乎意料
- 华为员工必须用华为手机?内部员工:主管用友商手机会“倒霉”
- 腾讯游戏发起对华为的挑战,或因后者对国内手机市场的影响力大跌
- 集录音转写、拍照翻译为一体,搜狗AI录音笔E2带你开启智慧办公新体验
- 专心做好产品、助力优秀企业提效率,刘润谈华为办公宝创新
- 别着急抢小米11,荣耀V40将登场,颜值比肩华为Mate40
- 美媒:美国拉小弟搞开放网络规范摆脱华为 但更多中国公司加入竞争搅黄美方计划
- 断供华为后,台积电将在日本设研发中心!还有望建设首座半导体厂
- 国产芯片巨头成功逆袭!华为有了“接班人”?这次连高通都没辙了