光子算数白冰:详解光子AI芯片落地进展与研发路径|GTIC2020( 二 )
 文章插图
文章插图
计算卡封装有光子协处理引擎模块 , 散热器、驱动、控制器、TIA、一些计算控制部分和赛灵思FPGA芯片 , 数据在光电之间形成循环流动 。 光的定位为电做协处理加速 。
其中光子协处理引擎模块用的是两个QSFP28的光通信接口(每个都是100GB/s) , 光通信物理接口非常成熟 , 其光学带宽大约达200GB/s , 典型功耗达7W , 算力在1.2TOPS左右 。 该模块支持热插拔 , 不需要经过预调 , 内部封装了一些适合于用光学做的特殊的算子函数 , 比如随机投影、高维空间变换映射、压缩、小规模卷积、时间序列等高算子 。 现在该模块还比较初步 , 白冰透露道 , 下一阶段 , 光子算数会进一步扩大其规模 。
光子协处理引擎模块里面是两层结构 , 上面是控制模组 , 其二级控制缓存处理随时可以换 , 以适应下一步软件迭代;下面是光学运算模组 , 包含整个光学计算部分 , 其中集成了大量的光学单元 , 为了一些特定的函数 , 可以做低延时、低能耗的变换过程 。
 文章插图
文章插图
完整计算过程是FPGA接收的数据从电接口进来 , 经过驱动放大 , 驱动光芯片上的调优器 , 把信号再返到光上 , 经过片内传输完成变换 , 然后再变成电信号返回 。
目前光子算数已将一些光电混合AI加速计算服务器提供给机房和IDC试用与测试 , 接口是标准的PCIe口 。 此外 , 其服务器也与一些国产操作系统和CPU厂商做了适配 。
 文章插图
文章插图
白冰坦言 , 该服务器目前性能仍较有限 , 70W运行功耗下 , 大概能做三四十路的视频同步处理 , 跟纯电比没有那么强 。
下一步 , 他们考虑将光的部分带宽扩大 , 进一步提升算力 。 当前在光通信领域 , 100GB/s是主流 , 200GB/s比较少 , 400GB/s、800GB/s主要有一些大厂在做 , 目前还没推出产品 。 尽管做这块成本较高 , 但这是比较切实可行的已有方案 。
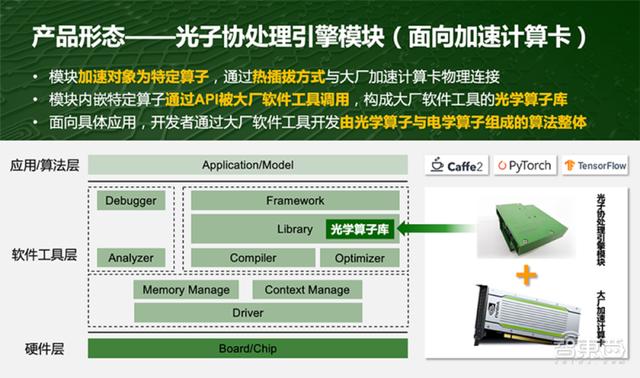
二、热插拔式模块 , 可由大厂软件调用接着白冰谈到第二个话题 , 光学芯片的产品定位 , 即这个东西做完之后 , 卖给谁?
如果想在云端替代NVIDIA GPU , 是非常困难的 , 其核心竞争力在于它的软件工具 。 把电和光放到一张卡上 , 要开发完整的软件套件 , 工作量非常大且代价很高 。 当然云端加速计算卡也可以做定制化 , 但定制化在云端的适用空间会相对有限 , 这是做云端AI芯片的所有公司共同面临的窘境 。
光子算数为什么选择做成热插拔方式?实际上 , 这是将适合用光学做的特定算子封装到光学模块里 , 通过热插拔接口和国内大厂的加速计算卡插在一起 , 这种接口制都是成熟的 , 开发者使用大厂的软件工具 , 即可通过API调用光子算数的模块内嵌特定算子 。 面向具体应用 , 开发者通过大厂软件工具 , 开发由光子算数的光学算子与大厂原有的电学算子组成的光电混合算法整体 。
 文章插图
文章插图
光子算数对自己的市场定位是提供传统加速计算卡的升级组件 , 使传统加速计算卡提升性能、降低能耗、降低成本 , 不受制于软件工具 。 消费者依然买大厂的卡和工具 , 如需升级 , 即可选用光子算数的模块 。
白冰提了一个形象的比喻 , 用一张传统卡加上光子协处理引擎模块的效果 , 相当于给汽车配了一个涡轮增压 。
 文章插图
文章插图
三、研发实施路径:算法先行 , 硬件跟进白冰还谈到关于研发路线的建议 。 他们研发的内容是系统性工程 , 相较于设计新型的光学计算单元 , 难度是可以克服的 。