来自Google:DELG,统一全局和局部特征的实例识别研究
作者:Cam Askew and André Araujo
编译:ronghuaiyang
导读
本文介绍了Google AI在实例识别领域的最新进展DELG , 将全局和局部特征的提取统一到了一个模型中 。
论文:
代码:https://github.com/tensorflow/models/tree/master/research/delf
Instance-level recognition (ILR)是识别一个的特定实例的计算机视觉任务 , 而不仅仅是它所属的类别 。 例如下图中 , 我们希望得到的是“梵高的星空” , “巴黎的凯旋门”而不是“后印象派绘画”以及“拱门”这样的标签 。 实例识别问题存在于许多领域 , 如地标、艺术品、产品或商标 , 并且在视觉搜索应用、个人照片管理、购物等领域都有应用 。 在过去的几年中 , 谷歌对于ILR的研究贡献包括:Google Landmarks Dataset,Google Landmarks Dataset v2 (GLDv2)以及新的模型包括 DELF 和Detect-to-Retrieve 。
 文章插图
文章插图
对于自艺术品、地标和产品 , 有三种类型的图像识别问题 , 分布具有不同级别的标签(基本、细粒度、实例) 。 在我们的工作中 , 我们关注于实例识别 。
在本文中 , 我们的重点是在ECCV ' 20上的Instance-Level Recognition研讨会上的一些结果 。 这个workshop的内容包括“DEep Local and Global features” (DELG) , 最先进的图像特征实例识别模型 , 并给出了DELG以及其他一些ILR技巧的开源代码 。 会中同时还提出了基于GLDv2的两个新的里程碑式挑战(关于识别和检索任务) , 以及扩展到其他领域的未来ILR挑战:艺术品识别和商品品检索 。 研讨会的长期目标和挑战是通过统一来自不同领域的研究工作流程 , 促进ILR领域的进步 , 并推动该领域的最新进展 , 迄今为止 , 这些研究工作大多是用来解决单独的问题的 。
DELG:深度局部和全局特征有效的图像表示是解决实例识别问题的关键 。 通常需要两种类型的表示:全局和局部图像特征 。 全局特征概括了图像的全部内容 , 导致一种紧凑的表示 , 但舍弃了实例中比较独特的视觉元素的空间排列信息 。 另一方面 , 局部特征包括关于特定图像区域的描述和几何信息 , 它们在描绘同一物体的图像匹配时特别有用 。
目前 , 大多数依赖这两种特征的系统需要使用不同的模型分别利用它们 , 这会导致冗余计算 , 降低整体效率 。 为了解决这个问题 , 我们提出了DELG , 一个用于局部和全局图像特征的统一模型 。
DELG模型利用了一个全卷积神经网络 , 它有两个不同的头:一个用于全局特征 , 另一个用于局部特征 。 利用深度网络层的特征图进行聚合 , 得到全局特征 , 有效地总结了输入图像的显著特征 , 使模型对输入的细微变化具有更强的鲁棒性 。 局部特征分支利用中间特征图来检测重要的图像区域 , 在注意力模块的帮助下 , 产生描述符 , 通过让描述符具有可区分性的方式来表示相关的局部内容 。
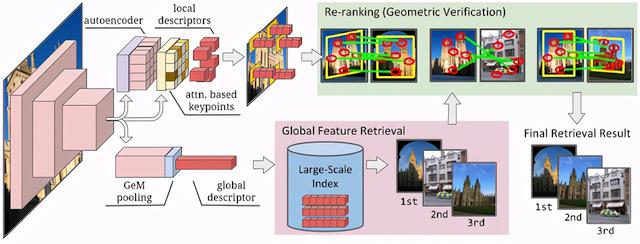 文章插图
文章插图
我们提出的DELG模型(左) 。 全局特征可用于基于检索的系统的第一阶段 , 有效地选择最相似的图像(下) 。 然后利用局部特征对top-level的结果进行重新排序(右上) , 提高系统的精度 。
这种新颖的设计可以进行高效的推理 , 因为它可以在单一模型中提取全局和局部特征 。 第一次 , 我们证明了这样一个统一的模型可以端到端训练 , 并为实例识别任务提供最先进的结果 。 与以往的全局特征相比 , 该方法的平均平均精度比其他方法高7.5% , 在局部特征重排序阶段 , 基于delg的结果比之前的工作提高了7% 。 整体而言 , DELG在GLDv2识别任务上的平均准确率达到了61.2% , 除了2019 challenge中的两种方法外 , 超过了其他的所有方法 。 注意 , 2019 challenge中的所有方法都进行了复杂模型的集成 , 而我们的结果只使用一个单一的模型 。
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 三星公布2021年款电视阵容:屏幕技术大升级 整合Google Duo等服务
- 全球手机芯片界迎洗牌:高通第二,第一来自中国,却不是华为
- Google Assistant新年新技能:为你唱上一首“新年歌”
- Google Chrome开发团队正探索通过扩大浏览器缓存解决性能问题
- YouTube称找到有力证据表明盗版上传者和DMCA通知来自同个IP
- 来自华为的决绝,忍痛割爱卖掉荣耀,是断臂自保还是有意为之?
- vivo Y31新机现身Google Play!将搭载了骁龙662芯片
- Google宕机45分钟,全世界网友急疯了
- 拍拍背包玩转您的手机,由Google与新秀丽智能纤维技术