Kafka支持的分布式架构超越经典软件设计的五个原因( 二 )
4-独立没有公司希望仅在供应链中拥有一个供应商 , 尤其是当涉及该公司的核心服务:软件时 。大多数依赖大型机的公司就是这种情况 。IBM主导了这一市场 , 占全球所有大型机的90%以上 。相反 , 公共云提供商正在以健康的方式相互竞争 , 导致价格在过去五年左右的时间内大幅下降 。
即使该公司决定拥有自己的数据中心(有时会发生这种情况) , 但由于该领域的市场多样化 , 因此它与特定的供应商也没有任何关系 。
5—复杂性最后 , 当大公司使用分布式系统将其后端基础架构迁移到云时 , 他们可以及时开发复杂的后端服务 。我的意思是 , 前端服务执行的许多操作现在都可以在后端中完全编码 。之所以如此 , 是因为在大多数情况下 , 当他们仅使用大型机时 , 便无法在大型机体系结构内完成诸如使用人工智能进行图像分析之类的操作 。
结果 , 大多数时候公司会使用前端来执行这些操作 , 甚至使用特定的服务来提供这些操作 。相反 , 当选择微服务架构时 , 可以在没有任何主要技术障碍的情况下实现此操作 。
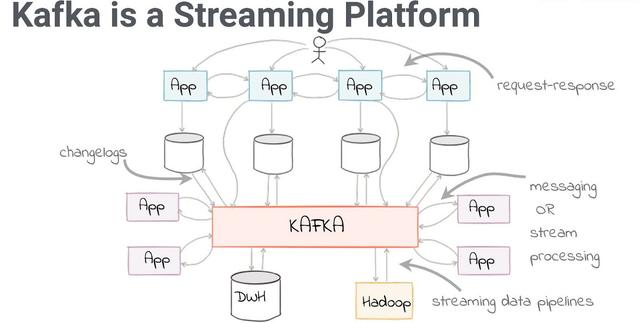
Kafka既然我们已经讨论了拥有一个完整的分布式平台的重要性 , 那么让我们来谈谈可用于支持此类设计的开源解决方案的类型 。Apache Kafka是用于管理和编排消息的最流行的消息代理组件之一 。已有10多年的历史了 , Kafka已成为几乎所有大型和基于云的体系结构中的关键组件 。
长话短说 , Kafka被微服务 , 服务或第三方应用程序(如Hadoop)用作消息交换以进行数据分析 。
 文章插图
文章插图
> Kafka by Confluent
架构注册表通过Kafka生成和使用的数据的完整性和控制权由Schema Registry进行 。所有治理 , 规则和结构都在Avro文件中定义 , 并且Schema Registry确保在Kafka上仅允许符合这些标准的消息 。
Docker大多数公共云提供商都提供Eka之类的KaaS(Kafka即服务)选项 , 并且像Confluent这样的公司也为本地数据中心提供客户支持 。
在使用Kafka和Schema Registry开发微服务时 , 大多数时候我们需要在本地运行这些组件以测试我们的软件 。这是我们使用Docker的主要原因之一(当然是众多原因之一) 。使用Docker Compose , 我们能够在个人计算机中运行多个容器 , 从而使我们能够同时运行Kafka和Schema Registry 。
为此 , 我们需要使用以下图像创建一个名为Dockerfile的文件:
FROM confluentinc/cp-kafka-connect:5.1.2
ENV CONNECT_PLUGIN_PATH="/usr/share/java,/usr/share/confluent-hub-components"
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latest
接下来 , 我们将创建名为docker-compose.yml的docker compose文件
最后 , 让我们在本地启动容器 。
$ docker-compose up
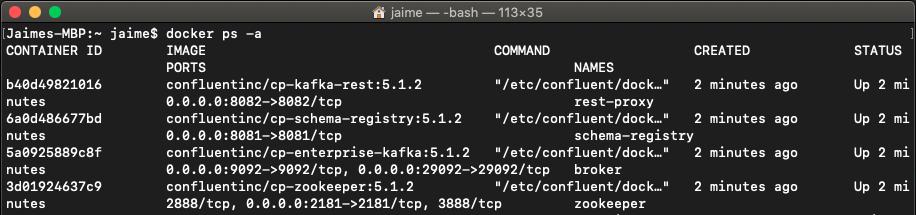
当我们执行命令docker ps -a时 , 我们可以看到我们的容器正在运行 。
 文章插图
文章插图
如果您愿意 , 我已经在github中包含了此代码 。
另外 , 您也可以使用由Marcos Vallim开发的令人敬畏的Java组件运行嵌入的Kafka和Schema Registry 。
Spring Boot微服务现在是时候创建我们的微服务了 。这里的想法是用Java创建两个微服务 。一个名为kafka-holder的人将包含一个执行付款的API端点 。收到此HTTP请求后 , 它将向Kafka发送一个Avro事件 , 并等待响应 。 -holder
然后 , 服务kafka-service将使用来自Kafka的此消息 , 处理付款 , 并产生一个新事件 , 说明是否已处理付款 。 -service
付款请求的Avro事件定义如下 。
此处创建的体系结构使用Kafka和架构注册表来协调消息 。
- 三星环保电视遥控器介绍:融入再生塑料 支持太阳能充电
- CES 2021:JBL发布新款耳机 支持自适应噪声消除功能
- Redmi Note 9T宣布:奥利奥四摄 支持NFC
- 三星Galaxy A32 5G支持页面在官网上线
- 三星发布Galaxy Chromebook 2 配备QLED显示屏和特殊手写笔支持
- 快看 | realme发布新机V15:支持50W闪充,售价1399元起
- 三星Galaxy A52 5G通过3C认证 支持最高15W快速充电
- 台积电强大背后,离不开荷兰巨头的支持,独占61台EUV光刻机
- 英特尔Z590主板规格曝光 将支持PCIe 4.0
- 小米11支持n28频段吗是5g手机吗n28频段什么意思