GPU到底有多快?( 三 )
 文章插图
文章插图
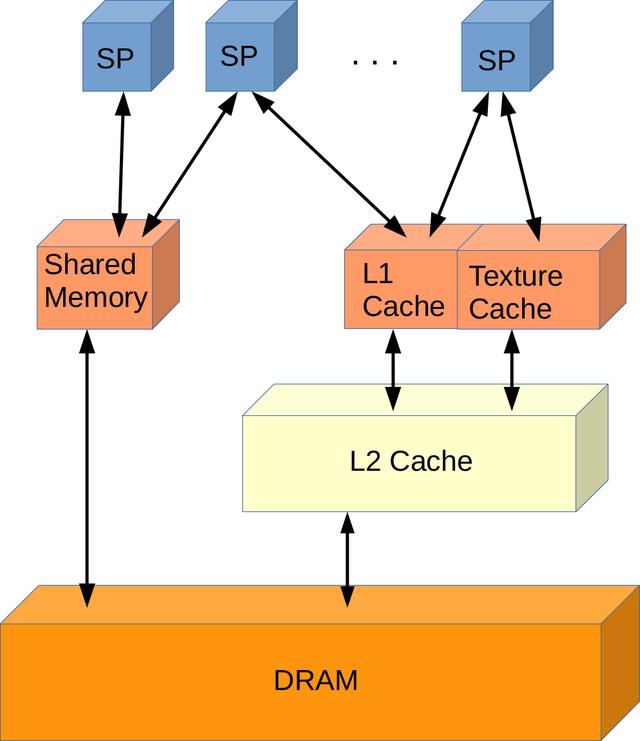
> Pascal Memory Hierarchy (Image by author)
【GPU到底有多快?】最后 , 介绍了NVLink技术 。背后的想法是 , 任何4-GPU和8-GPU系统配置都可以解决相同的问题 。甚至 , 使用InfiniBand?和100 Gb以太网将几组多GPU系统互连在一起 , 以形成更大 , 功能更强大的系统 。
伏打架构一块Volta板上最多可包含84个SM和八个512位内存控制器 。每个SM具有64个FP32 CUDA内核 , 64个INT32 CUDA内核 , 32个FP64 CUDA内核 , 8个用于深度学习矩阵算术的张量内核 , 32个LD / ST单元 , 16个SFU 。每个SM分为4个处理块 , 每个块包含一个新的L0指令高速缓存 , 以提供比以前的指令缓冲区更高的效率以及带有调度单元的warp调度程序 , 这与Pascal的2分区设置相反 , 每个子核心warp都有两个调度端口 调度程序 。这意味着Volta失去了在单个时钟周期内从线程发出第二条独立指令的能力 。
 文章插图
文章插图
> Volta Streaming Multiprocessor (Image by author)
引入了合并的128 KB L1数据高速缓存/共享内存 , 提供了96 KB的共享内存 。HBM2带宽也得到了提高 , 获得900 GB / s 。此外 , 完整的GPU总共包括6144 KB的L2缓存 , 其计算能力由7.0代码表示 。
 文章插图
文章插图
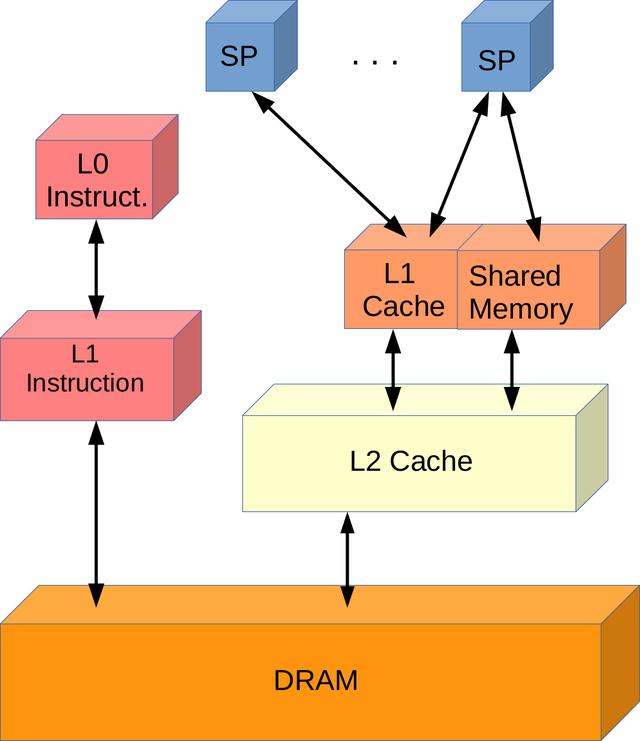
> Volta Memory Hierarchy (Image by author)
但是 , 最大的变化来自其独立的线程调度 。以前的体系结构以SIMT方式执行扭曲 , 在32个线程之间共享一个程序计数器 。在发生分歧的情况下 , 活动掩码指示在任何给定时间哪些线程处于活动状态 , 而使某些线程保持不活动状态并针对不同的分支选项序列化执行 。Volta包括一个程序计数器和每个线程的调用堆栈 。它还引入了调度优化程序 , 该调度程序确定必须将来自同一线程束的哪些线程必须一起执行到SIMT单元中 , 从而提供更大的灵活性 , 因为线程现在可以以子线程束粒度分散 。
Volta的最新突破功能称为Tensor Core , 与以前的Pascal P100加速器相比 , 它在深度学习应用中的速度提高了12倍 。它们本质上是混合精度FP16 / FP32内核的阵列 。640个张量核中的每个核都在4x4矩阵上运行 , 并且它们的关联数据路径是自定义设计的 , 以提高此类矩阵上运算的浮点计算吞吐量 。每个张量核心每个时钟执行64个浮点融合乘加(FMA)操作 , 为训练和推理应用提供多达125 TFLOPS 。
此外 , 第二代NVLink为多GPU系统配置提供了更高的带宽 , 更多的链接和改进的可伸缩性 。与GP100上的4NVLink链接和160 GB / s的总带宽相比 , Volta GV100最多支持6条NVLink链接和300 GB /秒的总带宽 。
图灵(不是全新的)架构NVIDIA首席执行官黄仁勋(Jen-Hsun Huang)对Pascal , Volta和Turing之间的架构差异提供了有趣的答复 。他基本上解释说 , Volta和Turing具有不同的目标市场 。Volta适用于大规模培训 , 最多可连接八个GPU , 具有最快的HBM2 , 以及其他专门用于数据中心的功能 。另一方面 , 图灵在设计时考虑了三个应用程序:专业可视化 , 视频游戏和使用Tensor Core的图像生成 。实际上 , 图灵具有与Volta 7.x相同的计算能力 , 这就是为什么我说图灵不是一种全新的体系结构 。
最杰出的成就是:使用GDDR6内存并引入了RT内核 , 这些RT内核可以渲染逼真的3D游戏和复杂的专业模型:
 文章插图
文章插图
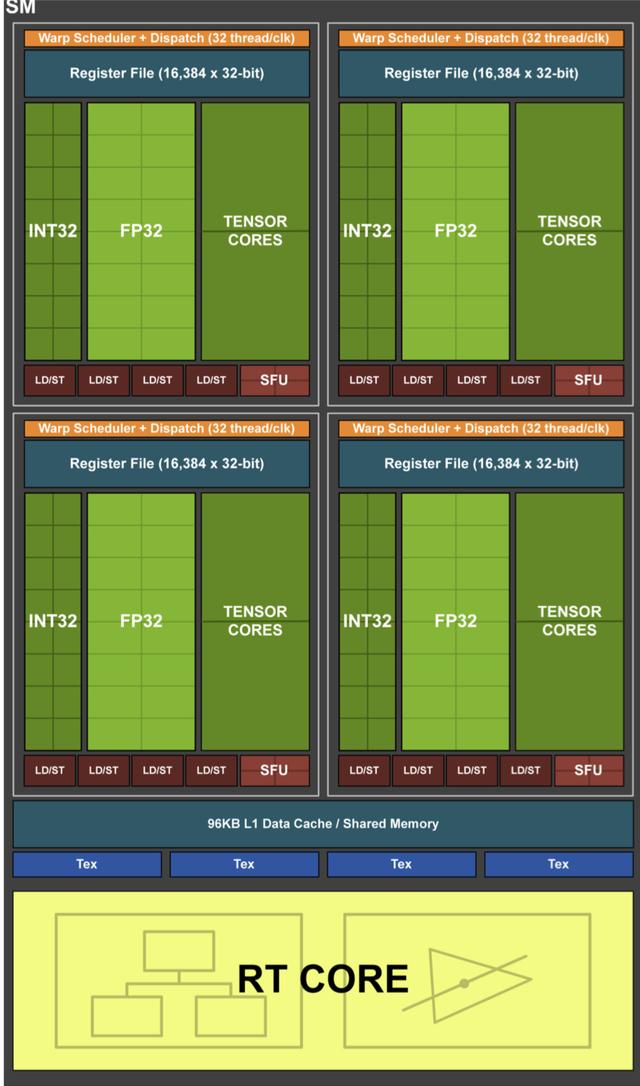
> Turing Streaming Multiprocessor. Source:NVIDIA
- AMD 专利展现 MCM 模块化芯片设计,GPU 将采用多核封装
- Sonnet更新便携式eGPU Breakaway Puck系列产品线
- “滑向2022”新浪杯高山滑雪公开赛,与华为WATCH GT2 Pro一起雪战到底
- 英特尔Xe GPU在Linux 5.11上的性能表现不错
- 一文读懂,书架箱和落地箱到底哪个好?
- Win10 真的要兼容安卓 App 了,微软到底想玩什么
- 全球移动网速比拼:美国63兆,韩国166兆,中国网速有多快?
- 20款游戏实战!酷睿i7-10750H、锐龙9 4900H到底谁更强?
- 手机出现“自动更新”,到底要不要更新?答案已确认
- 华硕和宏碁即将推出发烧级笔电 采用AMD Zen 3 移动处理器和NVIDIA 3080 GPU