Elasticsearch查询速度为什么这么快?( 二 )
 文章插图
文章插图
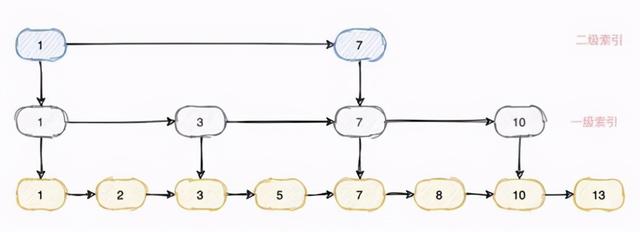
我们可以为最底层的数据提取出一级索引、二级索引 , 根据数据量的不同 , 我们可以提取出 N 级索引 。 当我们查询时便可以利用这里的索引变相的实现了二分查找 。
假设现在要查询 id=13 的数据 , 只需要遍历 1→7→10→13 四个节点便可以查询到数据 , 当数越多时 , 效率提升会更明显 。
同时区间查询也是支持 , 和刚才的查询单个节点类似 , 只需要查询到起始节点 , 然后依次往后遍历(链表有序)到目标节点便能将整个范围的数据查询出来 。
同时由于我们在索引上不会存储真正的数据 , 只是存放一个指针 , 相对于最底层存放数据的链表来说占用的空间便可以忽略不计了 。
平衡二叉树的优化但其实 MySQL 中的 InnoDB 并没有采用跳表 , 而是使用的一个叫做 B+ 树的数据结构 。
这个数据结构不像是二叉树那样大学老师当做基础数据结构经常讲到 , 由于这类数据结构都是在实际工程中根据需求场景在基础数据结构中演化而来 。
比如这里的 B+ 树就可以认为是由平衡二叉树演化而来 。 刚才我们提到二叉树的区间查询效率不高 , 针对这一点便可进行优化:
 文章插图
文章插图
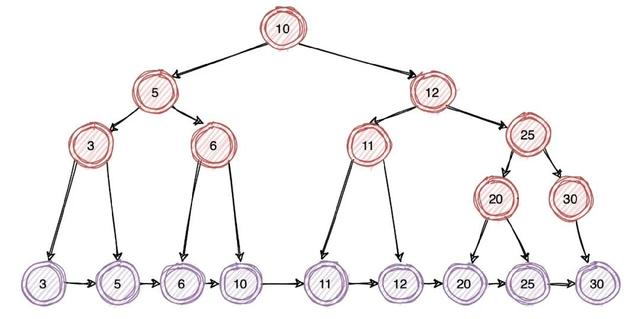
在原有二叉树的基础上优化后:所有的非叶子都不存放数据 , 只是作为叶子节点的索引 , 数据全部都存放在叶子节点 。
这样所有叶子节点的数据都是有序存放的 , 便能很好的支持区间查询 。 只需要先通过查询到起始节点的位置 , 然后在叶子节点中依次往后遍历即可 。
当数据量巨大时 , 很明显索引文件是不能存放于内存中 , 虽然速度很快但消耗的资源也不小;所以 MySQL 会将索引文件直接存放于磁盘中 。
这点和后文提到 Elasticsearch 的索引略有不同 。 由于索引存放于磁盘中 , 所以我们要尽可能的减少与磁盘的 IO(磁盘 IO 的效率与内存不在一个数量级) 。
通过上图可以看出 , 我们要查询一条数据至少得进行 4 次IO , 很明显这个 IO 次数是与树的高度密切相关的 , 树的高度越低 IO 次数就会越少 , 同时性能也会越好 。
那怎样才能降低树的高度呢?
 文章插图
文章插图
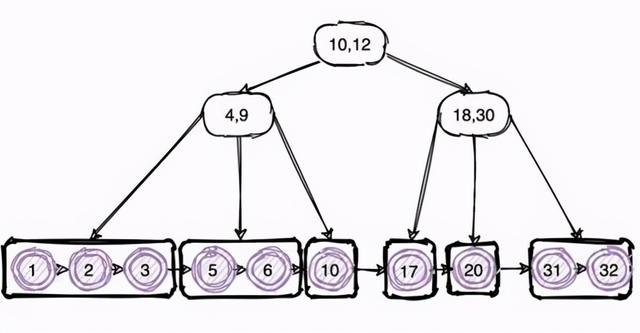
我们可以尝试把二叉树变为三叉树 , 这样树的高度就会下降很多 , 这样查询数据时的 IO 次数自然也会降低 , 同时查询效率也会提高许多 。 这其实就是 B+ 树的由来 。
使用索引的一些建议其实通过上图对 B+树的理解 , 也能优化日常工作的一些小细节;比如为什么需要最好是有序递增的?
假设我们写入的主键数据是无序的 , 那么有可能后写入数据的 id 小于之前写入的 , 这样在维护 B+树索引时便有可能需要移动已经写好数据 。
如果是按照递增写入数据时则不会有这个考虑 , 每次只需要依次写入即可 。 所以我们才会要求数据库主键尽量是趋势递增的 , 不考虑分表的情况时最合理的就是自增主键 。
整体来看思路和跳表类似 , 只是针对使用场景做了相关的调整(比如数据全部存储于叶子节点) 。
ES 索引MySQL 聊完了 , 现在来看看 Elasticsearch 是如何来使用索引的 。
正排索引在 ES 中采用的是一种名叫倒排索引的数据结构;在正式讲倒排索引之前先来聊聊和他相反的正排索引 。
 文章插图
文章插图
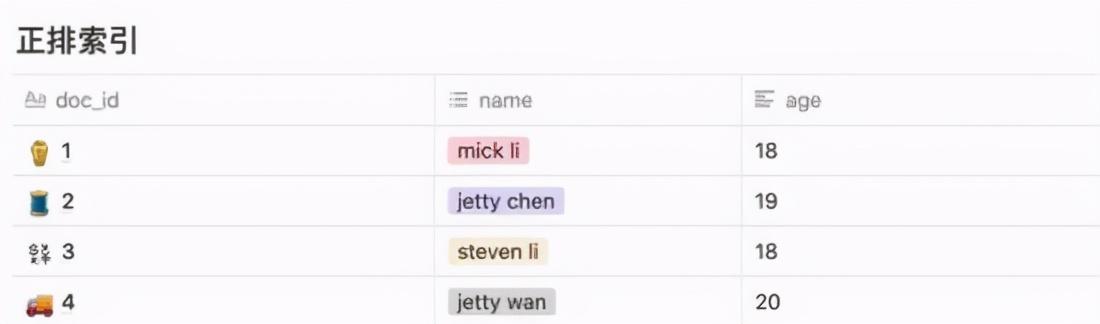
以上图为例 , 我们可以通过 doc_id 查询到具体对象的方式称为使用正排索引 , 其实也能理解为一种散列表 。
本质是通过 key 来查找 value 。 比如通过 doc_id=4 便能很快查询到 name=jetty wang , age=20 这条数据 。
- 首款7GB/s SSD!三星980PRO 1TB评测:永恒的1.8GB/s缓外写入速度
- 小米11 PK 小米10:传输速度提升1.6倍
- 4G速度变慢?运营商这波操作,让5G秒变“真香现场”
- 专家介绍如何判断智能手机被入侵:运行速度变慢、电池消耗过快以及卡顿
- 马化腾这招太高明!网友:只要我改名的速度够快,禁令就追不上我
- 怎样提高苹果6的运行速度?有这些问题就别救了,你用了几年了?
- 用户|4G速度慢了!5G也难逃“真香定律”
- 健康宝,保健康不保隐私?
- 西安奕斯伟硅产业基地项目建设刷新我国建设大硅片制造项目的最快速度
- 教你查询支付宝年度账单 快来看看今年你花了多少钱