美团外卖实时数仓建设实践( 二 )
如上图所示 , 拿到数据源后 , 会经过数据清洗 , 扩维 , 通过Storm或Flink进行业务逻辑处理 , 最后直接进行业务输出 。 把这个环节拆开来看 , 数据源端会重复引用相同的数据源 , 后面进行清洗、过滤、扩维等操作 , 都要重复做一遍 , 唯一不同的是业务的代码逻辑是不一样的 , 如果业务较少 , 这种模式还可以接受 , 但当后续业务量上去后 , 会出现谁开发谁运维的情况 , 维护工作量会越来越大 , 作业无法形成统一管理 。 而且所有人都在申请资源 , 导致资源成本急速膨胀 , 资源不能集约有效利用 , 因此要思考如何从整体来进行实时数据的建设 。
04
数据特点与应用场景
 文章插图
文章插图
那么如何来构建实时数仓呢?
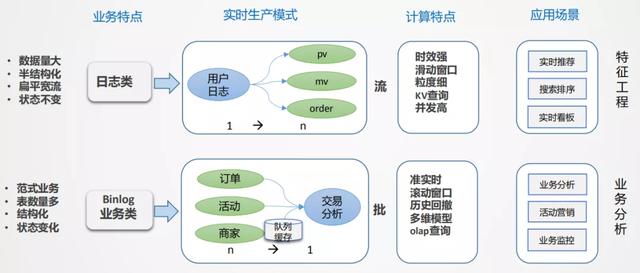
首先要进行拆解 , 有哪些数据 , 有哪些场景 , 这些场景有哪些共同特点 , 对于外卖场景来说一共有两大类 , 日志类和业务类 。
- 日志类:数据量特别大 , 半结构化 , 嵌套比较深 。 日志类的数据有个很大的特点 , 日志流一旦形成是不会变的 , 通过埋点的方式收集平台所有的日志 , 统一进行采集分发 , 就像一颗树 , 树根非常大 , 推到前端应用的时候 , 相当于从树根到树枝分叉的过程(从1到n的分解过程) , 如果所有的业务都从根上找数据 , 看起来路径最短 , 但包袱太重 , 数据检索效率低 。 日志类数据一般用于生产监控和用户行为分析 , 时效性要求比较高 , 时间窗口一般是5min或10min或截止到当前的一个状态 , 主要的应用是实时大屏和实时特征 , 例如用户每一次点击行为都能够立刻感知到等需求 。
- 业务类:主要是业务交易数据 , 业务系统一般是自成体系的 , 以Binlog日志的形式往下分发 , 业务系统都是事务型的 , 主要采用范式建模方式 , 特点是结构化的 , 主体非常清晰 , 但数据表较多 , 需要多表关联才能表达完整业务 , 因此是一个n到1的集成加工过程 。
- 业务的多状态性:业务过程从开始到结束是不断变化的 , 比如从下单->支付->配送 , 业务库是在原始基础上进行变更的 , binlog会产生很多变化的日志 。 而业务分析更加关注最终状态 , 由此产生数据回撤计算的问题 , 例如10点下单 , 13点取消 , 但希望在10点减掉取消单 。
- 业务集成:业务分析数据一般无法通过单一主体表达 , 往往是很多表进行关联 , 才能得到想要的信息 , 在实时流中进行数据的合流对齐 , 往往需要较大的缓存处理且复杂 。
- 分析是批量的 , 处理过程是流式的:对单一数据 , 无法形成分析 , 因此分析对象一定是批量的 , 而数据加工是逐条的 。
05
实时数仓架构设计
1. 实时架构:流批结合的探索
 文章插图
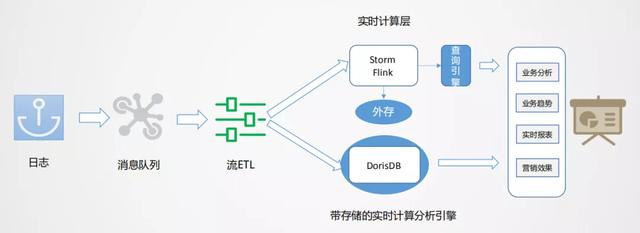
文章插图基于以上问题 , 我们有自己的思考 。 通过流批结合的方式来应对不同的业务场景 。
如上图所示 , 数据从日志统一采集到消息队列 , 再到数据流的ETL过程 , 作为基础数据流的建设是统一的 。 之后对于日志类实时特征 , 实时大屏类应用走实时流计算 。 对于Binlog类业务分析走实时OLAP批处理 。
流式处理分析业务的痛点?对于范式业务 , Storm和Flink都需要很大的外存 , 来实现数据流之间的业务对齐 , 需要大量的计算资源 。 且由于外存的限制 , 必须进行窗口的限定策略 , 最终可能放弃一些数据 。 计算之后 , 一般是存到Redis里做查询支撑 , 且KV存储在应对分析类查询场景中也有较多局限 。
- 一波未平一波又起,我买个菜就欠了一笔贷款?美团这次彻底没话说
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?
- 美团致歉:心怀对历史的敬畏 是做好产品的前提
- 王兴背后最重要的女人:北大毕业,如今是美团“第三号”人物
- 纪念馆|美团就“标签门”道歉,敬畏历史是做产品的前提
- 数据杀熟、屏蔽对手!频频“惹事”的美团遭反垄断诉讼
- 毫无敬畏之心!南京大屠杀遇难同胞纪念馆被标"休闲娱乐好去处",美团:立即改正
- 这些地方竟标注“室内玩乐”、“休闲娱乐的好去处”?美团紧急致歉
- 美团就乱贴标签道歉,敬畏历史是做产品的前提
- 「商界早知道」消息称滴滴青桔正寻求五亿美元融资;美团取消支付宝渠道遭反垄断诉讼;12306网售时间提前至5点