- MySql+Memcached架构的问题
实际MySQL是适合进行海量数据存储的 , 通过Memcached将热点数据加载到cache , 加速访问 , 很多公司都曾经使用过这样的架构 , 但随着业务数据量的不断增加 , 和访问量的持续增长 , 我们遇到了很多问题:1.MySQL需要不断进行拆库拆表 , Memcached也需不断跟着扩容 , 扩容和维护工作占据大量开发时间 。2.Memcached与MySQL数据库数据一致性问题 。3.Memcached数据命中率低或down机 , 大量访问直接穿透到DB , MySQL无法支撑 。4.跨机房cache同步问题 。众多NoSQL百花齐放 , 如何选择最近几年 , 业界不断涌现出很多各种各样的NoSQL产品 , 那么如何才能正确地使用好这些产品 , 最大化地发挥其长处 , 是我们需要深入研究和思考的问题 , 实际归根结底最重要的是了解这些产品的定位 , 并且了解到每款产品的tradeoffs , 在实际应用中做到扬长避短 , 总体上这些NoSQL主要用于解决以下几种问题1.少量数据存储 , 高速读写访问 。 此类产品通过数据全部in-momery 的方式来保证高速访问 , 同时提供数据落地的功能 , 实际这正是Redis最主要的适用场景 。2.海量数据存储 , 分布式系统支持 , 数据一致性保证 , 方便的集群节点添加/删除 。3.这方面最具代表性的是dynamo和bigtable 2篇论文所阐述的思路 。 前者是一个完全无中心的设计 , 节点之间通过gossip方式传递集群信息 , 数据保证最终一致性 , 后者是一个中心化的方案设计 , 通过类似一个分布式锁服务来保证将一致性,数据写入先写内存和redo log , 然后定期compat归并到磁盘上 , 将随机写优化为顺序写 , 提高写入性能 。4.Schema free , auto-sharding等 。 比如目前常见的一些文档数据库都是支持schema-free的 , 直接存储json格式数据 , 并且支持auto-sharding等功能 , 比如mongodb 。面对这些不同类型的NoSQL产品,我们需要根据我们的业务场景选择最合适的产品 。 Redis最适合所有数据in-momory的场景 , 虽然Redis也提供持久化功能 , 但实际更多的是一个disk-backed的功能 , 跟传统意义上的持久化有比较大的差别 , 那么可能大家就会有疑问 , 似乎Redis更像一个加强版的Memcached , 那么何时使用Memcached,何时使用Redis呢?如果简单地比较Redis与Memcached的区别 , 大多数都会得到以下观点:1 、Redis不仅仅支持简单的k/v类型的数据 , 同时还提供list , set , zset , hash等数据结构的存储 。2 、Redis支持数据的备份 , 即master-slave模式的数据备份 。3 、Redis支持数据的持久化 , 可以将内存中的数据保持在磁盘中 , 重启的时候可以再次加载进行使用 。
- Redis常用数据类型Redis最为常用的数据类型主要有以下:String
【redis 数据类型详解 以及 redis适用场景场合】Hash
List
Set
Sorted set
pub/sub
Transactions
在具体描述这几种数据类型之前 , 我们先通过一张图了解下Redis内部内存管理中是如何描述这些不同数据类型的:
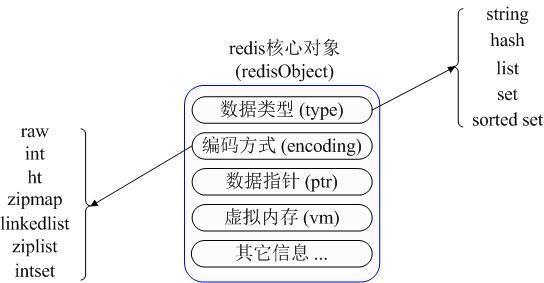
文章插图
首先Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:type代表一个value对象具体是何种数据类型 , encoding是不同数据类型在redis内部的存储方式 , 比如:type=string代表value存储的是一个普通字符串 , 那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的 , 当然前提是这个字符串本身可以用数值表示 , 比如:"123" "456"这样的字符串 。 这里需要特殊说明一下vm字段 , 只有打开了Redis的虚拟内存功能 , 此字段才会真正的分配内存 , 该功能默认是关闭状态的 , 该功能会在后面具体描述 。 通过上图我们可以发现Redis使用redisObject来表示所有的key/value数据是比较浪费内存的 , 当然这些内存管理成本的付出主要也是为了给Redis不同数据类型提供一个统一的管理接口 , 实际作者也提供了多种方法帮助我们尽量节省内存使用 , 我们随后会具体讨论 。