搜索引擎新架构:与SQL不得不说的故事
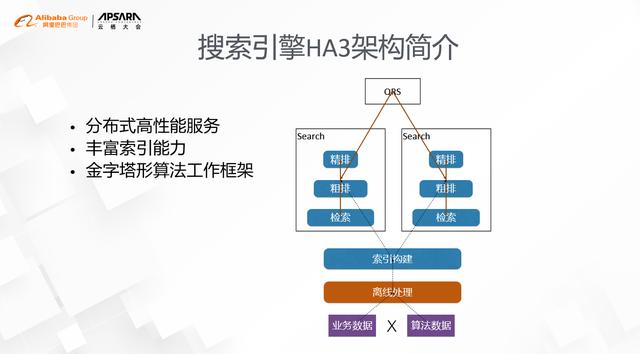
阿里巴巴搜索引擎HA3架构1.HA3架构分为在线和离线两部分
- 在线是一个传统的2层服务架构 , 分别叫做QRS和search 。 QRS负责接受用户请求 , 做一些简单处理之后把请求发给下面的search节点 , search节点负责加载索引并完成检索 , 最终由QRS汇集各个search节点的结果并返回给用户 。
- 离线部分分为两个环节 , 一个环节是数据的预处理 , 其核心的工作是把业务和算法维度的数据加工成对索引友好的大宽表 , 另一个环节是索引的构建 , 它的主要挑战是既要支持大规模的索引更新 , 也要保障索引是实时性 。
- 第一个是高性能的服务架构;
- 第二个是丰富的索引能力;
- 第三个是金字塔形的算法工作框架
 文章插图
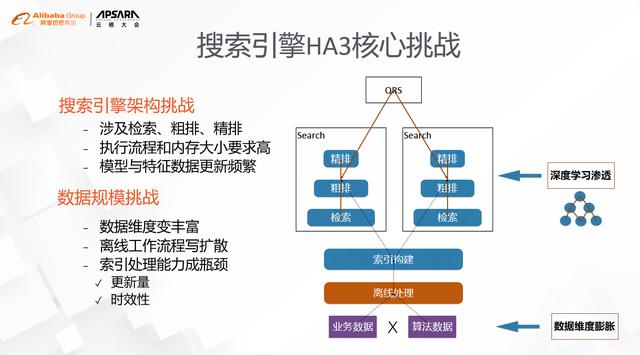
文章插图搜索引擎HA3核心挑战具体体现在2个方面 , 一个是深度学习的渗透 , 另一个是数据维度的膨胀 。
【搜索引擎新架构:与SQL不得不说的故事】1. 深度学习
它的使用范围 , 从早期的精排 , 逐步扩散到了粗排、检索 , 比如向量索引的召回 。 深度学习的引入本身也会带来2个问题:一个是深度模型的本身的网络结构通常比较复杂 , 对执行流程和模型大小都有非常高的要求 , 传统的pipeline工作模式是非常难以有效支持的;另外一个问题是模型和特征数据的实时更新也对索引的能力提出了很大的挑战 , 在线上百亿级别的更新是一个常态 。
2. 数据维度的膨胀
以电商领域为例 , 原来考虑的维度主要是买家、卖家这两个维度 , 现在得考虑位置、配送、门店、履约等等 , 同样是配送 , 有3公里5公里送的 , 有同城的 , 还有跨城的 , 像这样的例子还有很多 。 而搜索引擎离线的工作流程会把各个维度的数据join成一张大宽表 , 这会导致数据更新的规模成笛卡尔积的形式展开 , 在新场景下 , 无论是更新的量级还是时效性上都很难满足 。
 文章插图
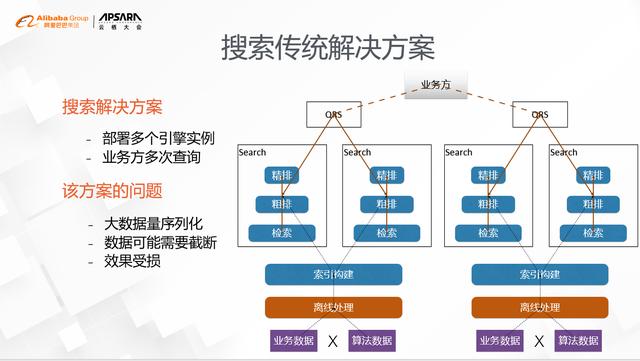
文章插图搜索传统解决方案就是根据业务数据维度的特点 , 把引擎分拆成过多个不同的实例 , 然后在业务层通过查询不同的引擎实例来得到结果 。 比如说饿了么的搜索引擎就有门店、商品等维度的数据 , 为了解决门店状态的实时变化对索引的冲击 , 可以部署两个搜索引擎实例 , 一个用来搜索合适的门店 , 另外一个用来搜索合适的商品 , 由业务方先查门店引擎再查商品引擎来完成 。 但这个方案有一个明显的缺点 , 那就是符合用户意图的门店非常多的时候 , 门店的数据需要从门店引擎序列化到业务方再发送给商品引擎 , 这里序列化的开销非常大 , 往往需要对返回的门店数目做一定截断 , 而截断的门店中很可能有更匹配用户意图的 , 这样对业务效果也会有比较大的影响 。 特别热门的商区 , 不管是对用户还是卖家 , 都是非常大的损失 。
 文章插图
文章插图HA3 SQL新的解决方案以数据库SQL的执行方式来重塑搜索 , 核心要点有3条 。
1.将原来带宽表的模式扩展成支持多表 , 每个表的索引加载、更新、切换做到相互独立 , 把原来需要离线join的操作变成在线查询时join 。2.彻底抛弃原有的pipeline的工作模式 , 以DAG图化的方式来执行 , 并将搜索的功能抽象成一个个独立的算子 , 与深度学习的执行引擎进行统一 。 3.以SQL的方式来表达图化的查询流程 , 这样不光用户使用起来简单 , 也可以复用SQL生态的一些基础功能 。 举个例子 , 电商个性化搜索技术里面 , 把商品、个性化推荐、深度模型等信息分别放到不同的表中 , 配合上灵活的索引格式 , 比如倒排索引、正排索引、KV索引等等 , 加上执行引擎本身可以支持并行、异步、编译优化等技术 , 不管是内存还是CPU都能得到有效利用 , 很轻松地就能解决业务上的各种问题 。
- NVIDIA 5nm架构猛料:流处理器超1.84万个
- MIPS架构厂商日渐式微 Linux报告其漏洞遭遇困难
- NVIDIA 5nm架构猛料曝光:1.84万个核心
- 喵博士资讯 | 中国手机在印度销量不降反升;英伟达正规划5nm架构显卡
- MIUI 12.5升级光锥动效架构:谁与争锋
- AMD Zen3架构锐龙5000H跑分曝光:单核性能暴涨近40%
- 苹果正在研发的搜索引擎能干的过谷歌吗?
- AMD确认Zen3架构新一代锐龙线程撕裂者处理器:要明年见了
- 美团|王慧文退休 美团调整组织架构
- 关于边缘计算与网络动态加速