即插即用,涨点明显!FPT:特征金字塔Transformer( 二 )
大量的实验表明 , FPT可以极大地改善传统的检测/分割网络:1)在MS-COCO test-dev数据集上 , 用于框检测的百分比增益为8.5% , 用于遮罩实例的mask AP值增益为6.0%;2)对于语义分割 , 分别在Cityscapes和PASCAL VOC 2012 测试集上的增益分别为1.6%和1.2%mIoU;在ADE20K 和LIP 验证集上的增益分别为1.7%和2.0%mIoU 。
2 本文方法
 文章插图
文章插图
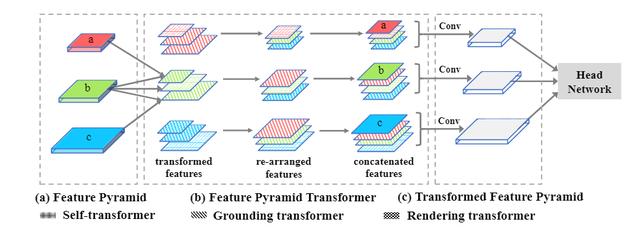
【即插即用,涨点明显!FPT:特征金字塔Transformer】图2. 本文提出的FPT网络的总体结构 。 不同的纹理图案表示不同的特征转换器 , 不同的颜色表示具有不同比例的特征图 。 “ Conv”表示输出尺寸为256的3×3卷积 。 在不失一般性的前提下 , 顶层/底层特征图没有rendering/grounding 转换器 。
如图2的FPT分解图所示 , 主要是三种transformer的设计:1)自变换器Self-Transformer(ST) 。 它是基于经典的同级特征图内的非局部non-local交互 , 输出与输入具有相同的尺度 。 2)Grounding Transformer(GT) 。 它是以自上而下的方式 , 输出与下层特征图具有相同的比例 。 直观地说 , 将上层特征图的 "概念 "与下层特征图的 "像素 "接地 。 特别是 , 由于没有必要使用全局信息来分割对象 , 而局部区域内的上下文在经验上更有参考价值 , 因此 , 还设计了一个locality-constrained的GT , 以保证语义分割的效率和准确性 。 3)Rendering Transformer(RT) 。 它是以自下而上的方式 , 输出与上层特征图具有相同的比例 。 直观地说 , 将上层 "概念 "与下层 "像素 "的视觉属性进行渲染 。 这是一种局部交互 , 因为用另一个远处的 "像素 "来渲染一个 "对象 "是没有意义的 。 每个层次的转换特征图(红色、蓝色和绿色)被重新排列到相应的地图大小 , 然后与原始map连接 , 然后再输入到卷积层 , 将它们调整到原始 "厚度" 。
1、Non-Local Interaction Revisited传统的Non-Local Interaction
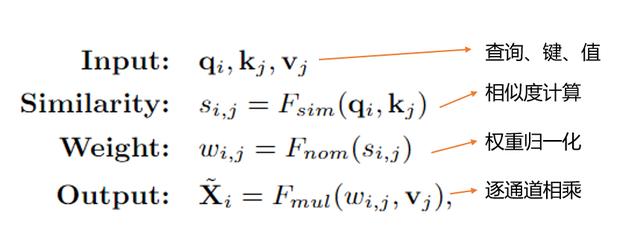 文章插图
文章插图
2、Self-Transformer
自变换器(Self-Transformer , ST)的目的是在同一张特征图上捕获共同发生的对象特征 。 如图3(a)所示 , ST是一种修改后的非局部non-local交互 , 输出的特征图与其输入特征图的尺度相同 。 与其他方法区别在于 , 作者部署了Mixture of Softmaxes(MoS)作为归一化函数 , 事实证明它比标准的Softmax在图像上更有效 。 具体来说 , 首先将查询q和键k划分为N个部分 。 然后 , 使用Fsim计算每对图像的相似度分数 。 基于MoS的归一化函数Fmos表达式如下:
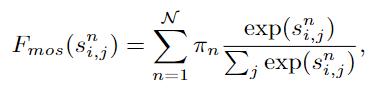 文章插图
文章插图
自变换器可以表达为:
 文章插图
文章插图
3、Grounding Transformer
Grounding Transformer(GT)可以归类为自上而下的非局部non-local交互 , 它将上层特征图Xct中的 "概念 "与下层特征图Xf中的 "像素 "进行对接 。 输出特征图与Xf具有相同的尺度 。 一般来说 , 不同尺度的图像特征提取的语义或语境信息不同 , 或者两者兼而有之 。 此外 , 根据经验 , 当两个特征图的语义信息不同时 , euclidean距离的负值比点积更能有效地计算相似度 。 所以我们更倾向于使用euclidean距离Fedu作为相似度函数 , 其表达方式为:
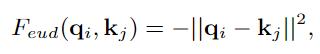 文章插图
文章插图
于是 , Grounding Transformer可以表述为:
 文章插图
文章插图