足够好的组合数据扩增( 四 )
分析:数据集统计 将 GECA 应用于 GEOQUERY 数据将两种语言中的问题分割的 full example overlap(在第 3 节末尾描述)增加了 5% , 将使用逻辑表单的查询分割增加了 6% , 将使用 SQL 表达式的查询分割增加了 9% , 与以下观察结果一致:查询分割的准确性提高比问题分割更大 。 在所有条件下 , 扩增都会使令牌共现重叠增加 3-4% 。
在对来自查询分割的 100 个合成样本的大规模人工分析中 , 评估它们的语法性和准确性(自然语言是否捕获逻辑形式的语义) , 我们发现 96%是语法正确的 , 98%是语义准确的 。
负面结果 我们在 Iyer 等人的 SCHOLAR text-to-SQL 数据集上进行了相应的实验 。 该数据集在大小 , 多样性和复杂性方面与 GEOQUERY 类似 。 然而 , 与 GEOQUERY 相比 , GECA 在 SCHOLAR 中的应用并没有带来任何改进 。 在查询分割上 , SQL 子查询的组合重用有限 。 相应地 , 扩增后的 full example overlap 保持为 0% , 令牌共现重叠仅增加 1% 。 这些结果表明 , 当 GECA 能够增加训练集和测试集中单词共现统计的相似度 , 以及当输入数据集表现出高度的递归性时 , GECA 是最成功的 。
5、低资源语言建模前面的两个部分都研究了条件模型 。与示例(4)一致 , GECA 提取和重用的片段实质上是同步词典条目 。 我们最初是用单语问题来激励 GECA 的 , 在这些问题中 , 我们只是希望改善关于格式正确性的模型判断 , 因此我们以一组语言建模实验作为结束 。
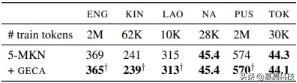
我们在五种语言(Kinyarwanda, Lao, Pashto, Tok Pisin, and a subset of English Wikipedia)上使用 Wikipedia dumps , 以及 Adams 等人的 Na 数据集 。 这些语言展示了 GECA 在各种形态复杂性方面的表现:例如 , Kinyarwanda 有一个复杂的名词类系统 , Pashto 有丰富的派生词法 , 而 Lao 和 Tok Pisin 在形态上相对简单 。 训练数据集从 10K 到 2M 令牌不等 。 与 Adams 等人一样 , 我们发现 5-gram modified Kneser-Ney 语言模型优于几种 RNN 语言模型 , 因此我们将 GECA 实验建立在 n-gram 模型上 。 我们使用 KenLM 中提供的实现 。
我们提取无间隙且最大大小为 2 个令牌的片段 , 环境被视为围绕所提取片段的 2 个令牌窗口 。 新用法仅针对数据中出现次数少于 20 次的片段生成 。 在 Kinyarwanda 语言中 , 基本数据集包含 3358 个句子 。 GECA 使用 913 个不同的模板和 199 个不同的片段生成额外的 913 个样本 。
我们发现最好的性能来自于在原始数据集和扩增数据集上训练一个语言模型 , 然后插值它们的最终概率 , 而不是像前面的章节那样直接在扩增数据集上训练语言模型 。 此插值的权重在验证数据集上确定 , 并选择 0.05、0.1 和 0.5 中的一个 。
结果见表 4 。 改进不是普遍的 , 并且比前几节要温和 。 但是 , GECA 可以减少多种语言之间的困惑度 , 而不会使其增加 。 这些结果表明 , 即使在条件任务和神经模型之外 , GECA 背后的替换原理也是一种鼓励合成的有用机制 。
 文章插图
文章插图
表 4:English(ENG) , Kinyarwanda(KIN) , Lao , Na , Pashto(PUS)和 Tok Pisin(TOK)的低资源语言建模困惑度 。
分析:样本和统计 在语言建模中 , GECA 作为一种平滑方案:它的主要作用是将大量数据移向可以出现在生产性上下文中的 n-grams 。 从这个意义上说 , GECA 的作用类似于所有 LM 实验中使用的 Kneser-Ney 平滑法 。 与 Kneser-Ney 不同的是 , GECA 的“上下文”概念既可以向前看 , 也可以向后看 , 并且可以捕捉更长时间的互动作用 。
合成句子的例子如图 5 所示 。 大多数句子都是语法性的 , 许多替换项保留了相关的语义类型信息(用 locations 代替 locations , 用 times 代替 times 等) , 但还是会生成一些格式错误的句子 。
- 卡内基梅隆大学提出了更好的强密码设置建议
- 惠普战66——可能是主流价位中最好的键盘体验
- 小米11效仿苹果不送充电器 或有更好的方式替代
- 越级的表现,三款音质超好的真无线耳机推荐
- 随时随地看猫狗,陌生人敲门也不害怕,就是这么神奇的组合
- 苹果砍单了 大范围取消用户订单 说好的用户是上帝呢?
- 适用于机器学习、数据科学和深度学习,不同价位最好的笔记本电脑
- 华为 Watch Fit 图赏:足够纤薄,也足够智慧
- Lava Be U在印度发布 低端手机辅以2+32GB内存组合
- 成果|高新技术成果在吉林组团“出道”,推进更多更好的成果落地!