自然语言处理在开放搜索中的应用( 二 )
 文章插图
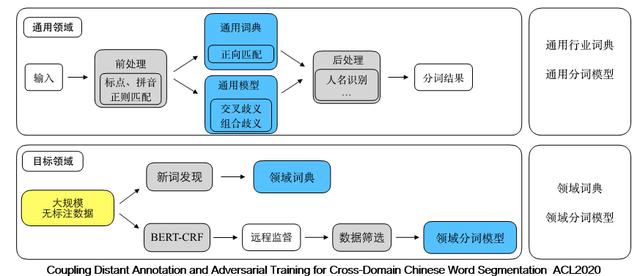
文章插图(上图为自动跨领域分词框架)用户只需要提供给我们一些自己业务的语料数据 , 我们就可以自动的得到一个定制化的分词模型 , 这不仅大大提升了效率 , 同时也更快满足客户的需求 。 通过这个技术 , 我们可以在各个领域获得比开源通用分词 , 更好的效果
 文章插图
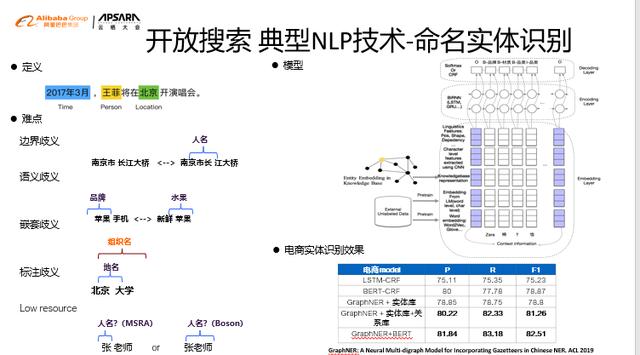
文章插图命名实体识别命名实体识别(NER) , 例如从query中提取人名 地名 时间等 。 挑战与困难NER在NLP领域研究非常多同时也面临很多的挑战 , 尤其在中文上由于缺乏天然分隔符 , 面临边界歧义、语义歧义、嵌套歧义等困难 。 **解决思路**? 下图右上角是我们在开放搜索中使用的模型架构图;? 在开放搜索中 , 很多用户都积累了大量词典实体库 。 为了充分利用这些词典 , 我们提出了一种在bert之上 , 有机融合知识的graphNer框架 。 从右下角的表格可以看出 , 在中文上能取得最好的效果;
 文章插图
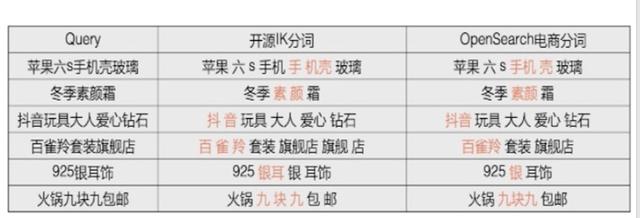
文章插图拼写纠错开放搜索分为4个纠错步骤包含了挖掘、训练、评估和在线预测 。 主要的模型根据统计翻译模型和神经网络翻译模型两套系统 , 同时在性能、展示样式和干预上有一套完备方法 。
 文章插图
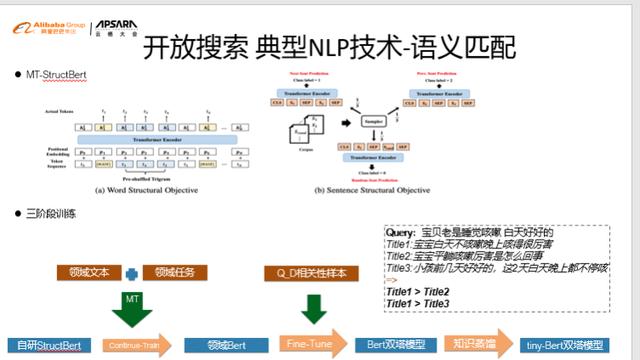
文章插图语义匹配深度语言模型的出现给很多NLP任务带来了跨越式的提升 , 尤其是在语义匹配等任务上 。 达摩院在bert上也提出了很多创新 , 提出了自研的StructBert 。 主要创新点在于在深度语言模型训练中 , 增加了字序/词序的目标函数 和更多样的句子结构预测目标函数 , 进行多任务学习 。 但是这样的通用的structbert是无法试用给开放搜索里成千上万个客户 , 成千上万个领域的 。 我们需要做领域适配 。 所以我们提出了语义匹配3阶段范式 。可以快速的为客户定制适合于自己业务的语义匹配模型 。
 文章插图
文章插图(具体的流程如图)
NLP算法产品化算法模块产品化的系统架构 , 包含了离线计算、在线引擎以及产品控制台 。 图中浅蓝色的部分是NLP在开放搜索上开放的算法相关功能 , 用户可以直接在控制台体验和使用 。
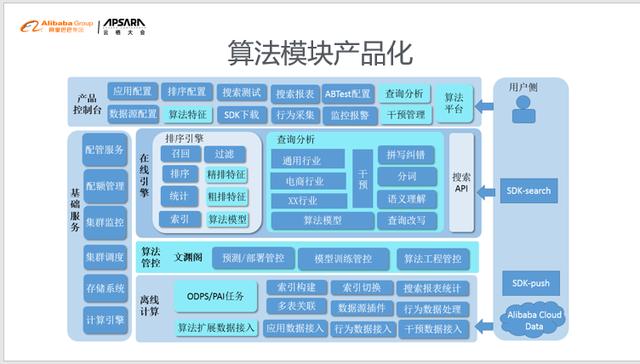 文章插图
文章插图以上就是本次云栖大会--“自然语言处理在开放搜索中的应用”的内容 。 如果您对搜索与推荐相关技术感兴趣 , 欢迎加入钉钉群内交流~
【开放搜索】新用户活动:阿里云实名认证用户享1个月免费试用
- 美媒:美国拉小弟搞开放网络规范摆脱华为 但更多中国公司加入竞争搅黄美方计划
- 最大飞行高度25米!小鹏飞行汽车亮相,试乘试驾将今年开放
- RHEL 9提升了x86_64处理器的入门要求
- 2020百度地图生态大会:开放平台十周年 为行业送出多个解决方案“大礼包”
- 联想IdeaPad 5 Pro系列笔记本发布 可选两种处理器和两种尺寸
- 联想推出搭载骁龙处理器的IdeaPad 5G
- 性能翻倍!飞腾首款8核桌面处理器腾锐D2000详解
- 苹果自研新处理器曝光:64核心
- 推进|我国今年将推进快递“进村”“进厂”“出海”构建日处理超10亿件寄递网络
- 支付处理公司Juspay发生数据泄漏:1亿用户信息在暗网出售