打开,体验流畅的单目三维手势技术( 二 )
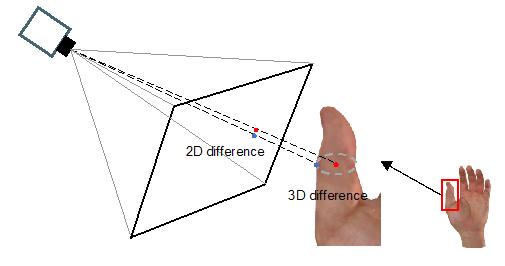
图 2:生成人手(左图)与真实人手(右图)的视觉差异
 文章插图
文章插图
图 3:生成数据与真实数据的标注差异
针对生成数据与真实数据存在的领域差异问题 , 早期研究人员利用数据集的先验知识 , 使生成数据与真实数据具有相似的预测结果 。 比如 Yujun Cai 等人 [3] 在三维人手姿态检测任务中约束生成数据与真实数据预测结果的相对深度范围 。 但是这种基于先验知识的约束只能限制生成数据与真实数据的输出满足预先设定的条件 , 并不能让网络自动挖掘两种数据集的共有特征 , 因此 , 一些学者开始研究显式的共有特征学习方法 。
领域迁移 [4,5] 是学习不同数据集间共有特征的常用方法 。 这类方法通过拉近真实数据与生成数据的特征来提取二者的共有信息 , 并且在图像分割 [6]、姿态检测 [7]、图像分类 [8] 等领域得到广泛应用 。 虽然拉近二者特征能够提升生成数据的泛化能力 , 但是由于领域差异的存在 , 不加区分地拉近生成数据与真实数据的特征 , 会增加优化的难度 , 导致无法收敛或者无法得到满意的性能 。 因此 , 有必要对神经网络的特征进行区分 , 在拉近二者特征的同时 , 保留领域独有的特征 , 消除领域差异带来的影响 。
基于这个思路 , 研究人员设计了自适应的特征对齐方法 , 让神经网络在训练过程中自适应地学习领域共有与领域独有特征 , 自动挖掘共有信息 , 同时降低生成数据与真实数据差异带来的优化困难问题 。
 文章插图
文章插图
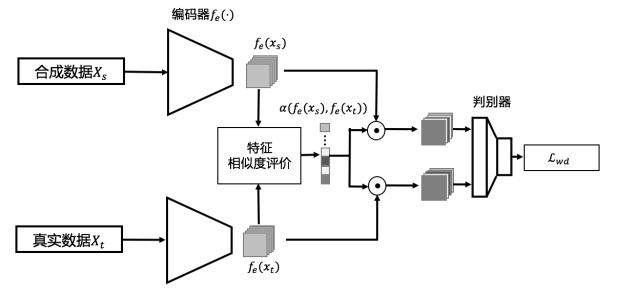
图 4:自适应的特征对齐方法示意图
如图 4 所示 , 本研究在常见判别网络基础上引入了特征相似度评价指标 , 利用该指标实现共有特征和独有特征的自适应学习 。 由于每个通道的特征是由同一个卷积核计算得到 , 因此假定深度网络的特征每个通道代表一种含义 。 该特征相似度评价公式如公式(1)所示:
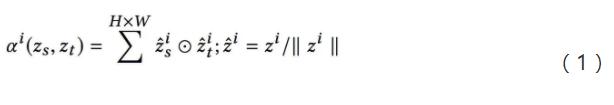 文章插图
文章插图
其中 , 代表的是第 i 个通道的特征 。
得到生成数据与真实数据特征逐通道的相似度后 , 将该相似度与原有特征相乘得到加权后的特征 。 通过判别器网络最小化新特征间的推土机距离 , 使生成数据和真实数据的共有特征尽可能相似 。 该过程的损失函数如公式(2)所示:
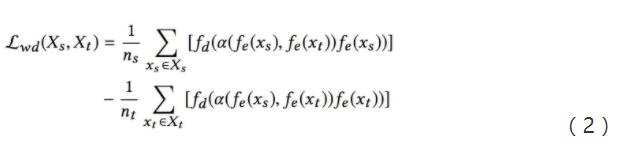 文章插图
文章插图
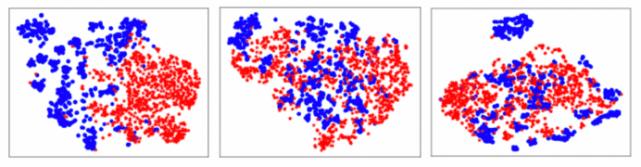
经过优化 , 权重大的特征在拉近后应该会更加接近 , 权重小的特征则会保持原有距离 。 使用 t-SNE [9] 对特征进行可视化 , 结果如图 5 所示 , 其中红色代表生成数据的特征 , 蓝色代表真实数据的特征 。
 文章插图
文章插图
图 5:直接联合训练、直接特征拉近训练和自适应特征对齐训练
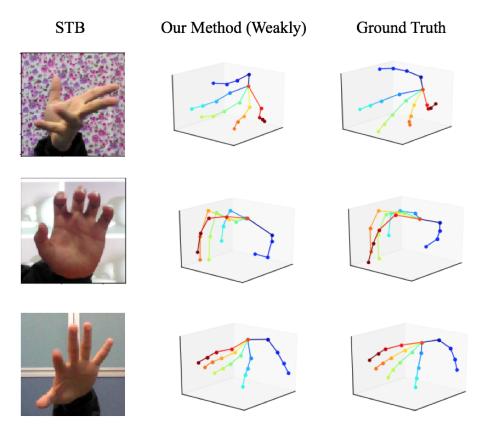
图 6 展示了该方法在 STB [10] 数据集上的可视化结果 。 虽然没有使用真实数据集的深度标注 , 但是仍然能够取得较为正确的预测结果 。
 文章插图
文章插图
图 6:弱监督情形人手三维姿态检测结果
基于显式教师网络的人手物理约束方法
在训练数据不充足的情况下 , 网络很容易输出不合理的手型 , 如图 7 所示:
 文章插图
文章插图
图 7:非正常手势示意图
现有提升人手合理性的方法大致分为两类:
一类 [11,12] 是借助人手模型将约束表示为人手模型的参数 , 通过限制这些参数的范围保证预测手势的合理性 。 但由于人手模型相比关键点是更高层次的抽象 , 因此需要较大的模型以及充足的训练数据才能获得令人满意的效果 。
- 集录音转写、拍照翻译为一体,搜狗AI录音笔E2带你开启智慧办公新体验
- 当下正流行,轻量化无线游戏鼠标代表作登场!赛睿Aerox 3 Wireless体验
- 拜拜扫描仪!微信打开这个功能,文档表格扫一扫秒变电子档
- 日本工程师:潘多拉魔盒被美国打开,中国办芯片大学只为打破禁令
- 开会再也不用手写,微信打开这个设置,会议纪要一键生成
- 骁龙888首次实现可变分辨率渲染 创造沉浸式游戏体验
- Facebook智能眼镜有望2021年上市 AR叠加体验或缺席
- ?什么叫专业?海信Hard Plus电竞显示屏打造极致游戏体验
- 三星8K电视率先获得8KA新规认证 增强沉浸音频体验
- 美国媒体:潘多拉魔盒被中国打开,韩国这项科技超越中国问鼎全球