基于神经网络的风格迁移目标损失解析( 二 )
所以这意味着深度学习方法的特点在于提取图像的风格 , 而不仅仅是通过对风格图像的像素观察 , 而是将预先训练好的模型提取的特征与风格图像的内容相结合 。 因此 , 从本质上说 , 要发现一个图像的风格 , womenxuyao 通过分析其像素来处理风格图像并将此信息提供给预先训练过的模型层 , 以便将提供的输入"理解"/分类为对象
如何做到这一点 , 我们将在下面一节中探讨 。
风格和内容基本思想是将图像的风格转换为图像的内容 。
因此 , 我们需要了解两件事:
· 图片的内容是什么
· 图像的风格是什么
松散地说 , 图像的内容是我们人类识别为图像中的对象的东西 。汽车 , 桥梁 , 房屋等 。 风格很难定义 。这在很大程度上取决于图像 。它是整体纹理 , 颜色选择 , 对比度等 。
这些定义需要以数学方式表达 , 以便在机器学习领域中实现 。
损失函数的计算首先 , 为什么要计算代价/损失?重要的是要理解 , 在这种情况下 , 损失只是原始图像和生成图像之间的差异 。 有多种计算方法(MSE , 欧氏距离等) 。 通过最小化图像的差异 , 我们能够传递风格 。
当我们从损失的巨大差异开始时 , 我们会看到风格转换不是那么好 。 我们可以看到风格已经转移 , 但是看起来很粗糙而且不直观 。 在每个代价最小化步骤中 , 我们都朝着更好地合并风格和内容并最终获得更好的图像的方向发展 。
我们可以看到 , 此过程的核心要素是损失计算 。 需要计算3项损失:
内容损失
风格损失
总(变动)损失
在我看来 , 这些步骤是最难理解的 , 因此让我们一一深入研究 。
请始终记住 , 我们正在将原始输入与生成的图像进行比较 。 这些差异就是代价 。 而我们希望将此代价降至最低 。
理解这一点非常重要 , 因为在此过程中还将计算其他差异损失 。
内容代价计算什么是内容代价? 正如我们之前发现的 , 我们通过图像对象定义图像的内容 。作为人类的事物可以识别为事物 。
了解了CNN的结构后 , 现在很明显 , 在神经网络的末端 , 我们可以很好地访问一个表示对象(内容)的层 。通过池化层 , 我们丢失了图像的风格部分 , 但是就获取内容而言 , 这是理想的 。
现在 , 在存在不同对象的情况下 , 可以激活CNN较高层中的特征图 。因此 , 如果两个图像具有相同的内容 , 则它们在较高层中应具有相似的激活 。
这是定义代价函数的前提 。
下图有助于了解如何展开该层以准备进行计算:
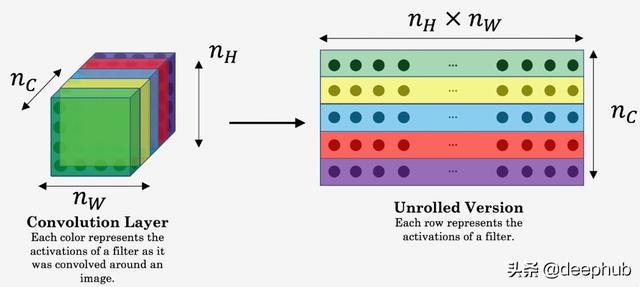 文章插图
文章插图
风格代价计算现在 , 它变得越来越复杂 。
确保了解图像风格和图像风格损失之间的区别 。两种计算是不同的 。一种是检测"风格表示"(纹理 , 颜色等) , 另一种是将原始图像的风格与生成的图像的风格进行比较 。
风格总代价分为两个步骤:
· 识别风格图像的风格 , 从所有卷积层中获取特征向量;将这些向量与另一层中的特征向量进行比较(查找其相关性)
· 原始(原始风格图像!)和生成的图像之间的风格代价 。 为了找到风格 , 可以通过将特征图乘以其转置来捕获相关性 , 从而生成gram矩阵 。
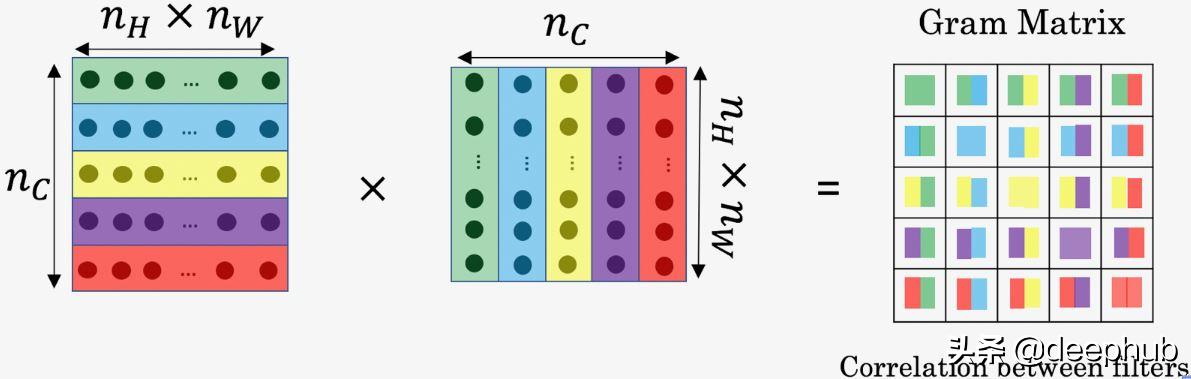 文章插图
文章插图
幸运的是 , CNN为我们提供了多个层次 , 我们可以选择正确地查找其风格 。比较各个图层及其相关性 , 我们可以确定图像的风格 。
因此 , 我们不使用图层的原始输出 , 而是使用单个图层的要素图的gram矩阵来标识图像的风格 。
第一个代价是这些矩阵之间的差异 , 即相关性的差异 。 第二个代价同样是原始图像和生成的图像之间的差异 。 这在本质上就是"风格转换" 。
- 微软新版电子邮件客户端截图曝光:基于网页端Outlook
- 曝光 | 小鹏或春节前推送NGP更新,基于高精地图可自动变道
- 华为鸿蒙手机太难了!引发开发者大吐槽:为何没有自己独特风格?
- 基于Spring+Angular9+MySQL开发平台
- 14款华为手机/平板公测EMUI 11:全部基于麒麟980
- AI赋能,让消防、用电更“智慧”
- 基于安卓11打造!魅族17系列将升级全新Flyme 8
- 谷歌为用户提供了基于AR的虚拟化妆体验
- 智能化社区是智慧城市重要的组成部分
- 风格各异的红米K20 Pro手机壳,个性随心显独特品位