对比PyTorch和TensorFlow的自动差异和动态模型( 二 )
一旦我们有了权重和偏差梯度 , 就可以在PyTorch和TensorFlow上实现我们的自定义梯度派生方法 , 就像将权重和偏差参数减去这些梯度乘以恒定的学习率一样简单 。
此处的最后一个微小区别是 , 当PyTorch在向后传播中更新权重和偏差参数时 , 以更隐蔽和"魔术"的方式实现自动差异/自动graf时 , 我们需要确保不要继续让PyTorch从最后一次更新操作中提取grad , 这次明确调用no_grad api , 最后将权重和bias参数的梯度归零 。
TensorFlow训练循环
def squared_error(y_pred, y_true):return tf.reduce_mean(tf.square(y_pred - y_true))tf_model = LinearRegressionKeras()[w, b] = tf_model.trainable_variablesfor epoch in range(epochs):with tf.GradientTape() as tape:predictions = tf_model(x)loss = squared_error(predictions, y)w_grad, b_grad = tape.gradient(loss, tf_model.trainable_variables)w.assign(w - w_grad * learning_rate)b.assign(b - b_grad * learning_rate)if epoch % 20 == 0:print(f"Epoch {epoch} : Loss {loss.numpy()}")PyTorch训练循环
def squared_error(y_pred, y_true):return torch.mean(torch.square(y_pred - y_true))torch_model = LinearRegressionPyTorch()[w, b] = torch_model.parameters()for epoch in range(epochs):y_pred = torch_model(inputs)loss = squared_error(y_pred, labels)loss.backward()with torch.no_grad():w -= w.grad * learning_rateb -= b.grad * learning_ratew.grad.zero_()b.grad.zero_()if epoch % 20 == 0:print(f"Epoch {epoch} : Loss {loss.data}")结论正如我们所看到的 , TensorFlow和PyTorch自动区分和动态子分类API非常相似 , 当然 , 两种模型的训练也给我们非常相似的结果 。
在下面的代码片段中 , 我们将分别使用Tensorflow和PyTorch trainable_variables和parameters方法来访问模型参数并绘制学习到的线性函数的图 。
绘制结果
[w_tf, b_tf] = tf_model.trainable_variables[w_torch, b_torch] = torch_model.parameters()with torch.no_grad():plt.figure(figsize = (12,5))ax = plt.subplot(111)ax.scatter(x, y, c = "b", label="samples")ax.plot(x, w_tf * x + b_tf, "r", 5.0, "tensorflow")ax.plot(x, w_torch * inputs + b_torch, "c", 5.0, "pytorch")ax.legend()plt.xlabel("x1")plt.ylabel("y",rotation = 0)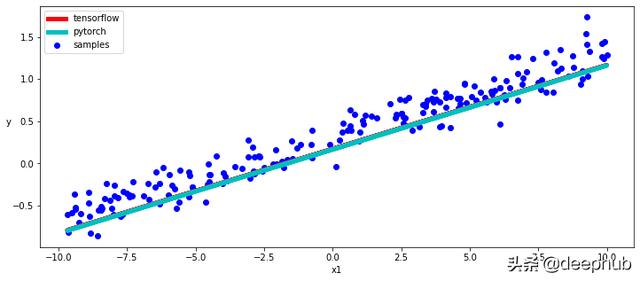 文章插图
文章插图
作者:Jacopo Mangiavacchi
本文代码:github/JacopoMangiavacchi/TF-VS-PyTorch
【对比PyTorch和TensorFlow的自动差异和动态模型】deephub翻译组
- 苹果M1、A14内核设计对比:差别很大
- 华为畅享20se和红米note9哪个好区别在哪 参数对比评测
- 荣耀v40pro对比vivox60pro哪个好区别在哪 性能谁更强
- realmev15和realmev3区别参数对比 哪个好性价比高
- 红米k40pro和荣耀30区别哪个好 不同点对比参数配置谁好
- iqoo7和红米k30至尊纪念版哪个好区别在哪 参数对比评测
- 小米11和红米k30pro哪个好性价比高 参数配置对比区别
- 华为nova8与小米10对比哪个好 参数配置区别性能评测
- 骁龙480和天玑720哪个好性能强 规格参数功能对比
- 骁龙732g和骁龙750g哪个好谁性能更强 参数对比评测