持续定义SaaS模式云数据仓库+AI( 二 )
二、What:能力与应用我们将该项目的名字叫Mars , 其最早是意味着Matrix和array , 当然现在已经不再局限于这两者 , 数据维度可以达到非常高的程度;第二是意味着我们向着比登月更高的目标出发 , 不断的挑战自己 。 那么我们为什么要做Mars呢?其主要原因有:
- 1.为大规模科学计算设计的:传统的大数据引擎编程接口对科学计算不太友好 , 框架设计也不是为科学计算模型考虑的;
- 2.传统科学计算大多基于单机 , 而大规模科学计算需要用到超算 , 并非普通人所能给予的能力;
- 3.传统SQL模型科学计算的处理能力不足 , 做一些简单的科学计算 , 比如矩阵转置等等 , 效率也是非常低;
- 4.目前R和Python基本上基于单机 , 其分布式扩展能力比较弱 。
 文章插图
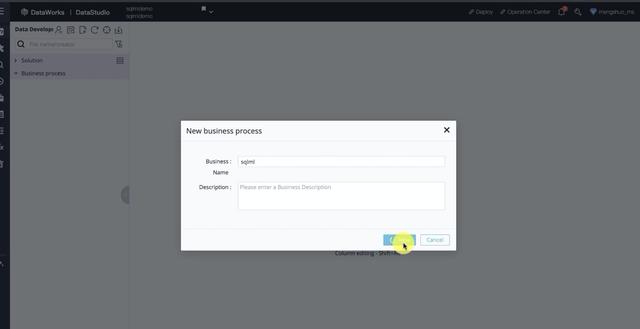
文章插图三、How:最佳实践下面是一个简单的SQLML的Demo介绍 。 首先 , 我们在DataWorks中新建一个工作流 , 会发现工作流中有很多组件 , 我们先建一个临时查询 , 如下图所示:
 文章插图
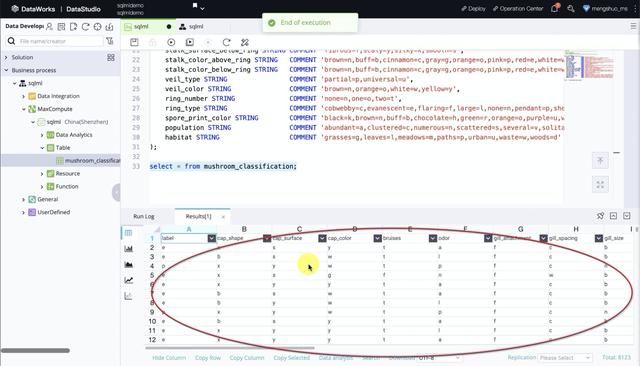
文章插图然后新建一张表 , 其中保存的是关于蘑菇的一些属性 , 根据这些属性数据 , 我们可以对其进行分类 。 表建立好之后 , 我们可以将数据导入 , 因为该数据集比较小 , 所以我们从本地上传csv文件 , 将列与表中的字段对应即可:
 文章插图
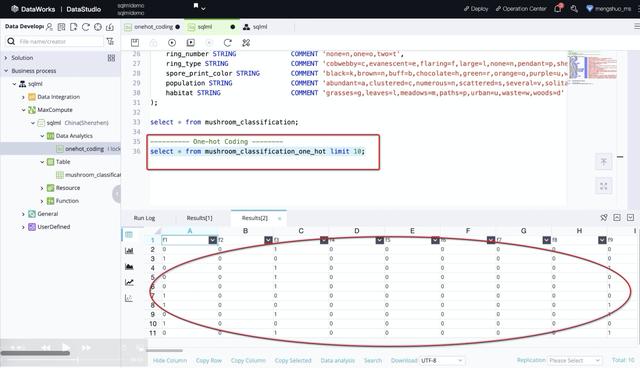
文章插图之后 , 我们需要对特征进行onehot编码 , 其结果如下图所示:
 文章插图
文章插图然后 , 我们将数据分成训练集和测试集 , 并且分别将训练集和测试集导入一张单独的表中 , 之后就可以创建模型了 , 这里我们用的是逻辑回归 , 一个常用的二分类算法:
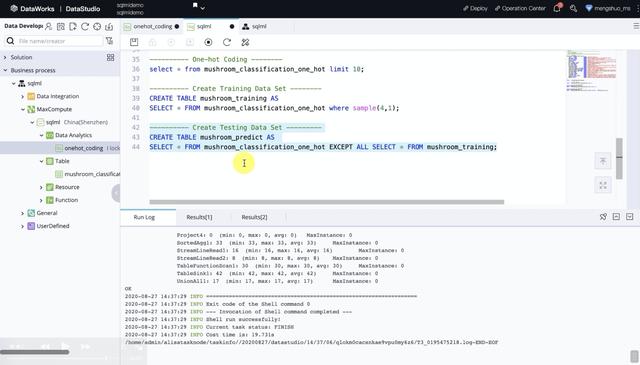 文章插图
文章插图运行模型 , 很便捷地就可以得到训练结果:
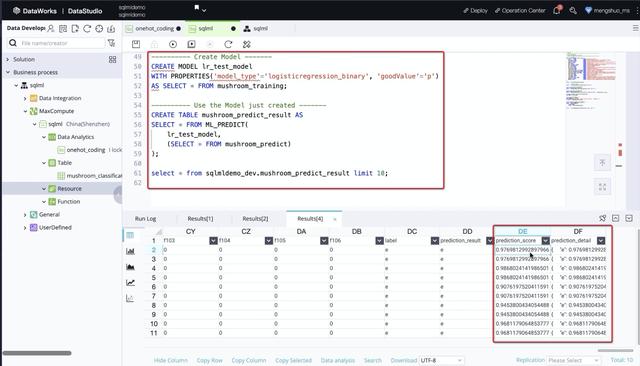 文章插图
文章插图通过上面的Demo , 我们很容易的就完成了一次机器学习的训练过程 , 其过程类似与使用SQL中的UDF , 简便、高效 。 上面Demo介绍的是SQLML , 如果想使用Mars也非常简单 , 我们只需要拖拽PyODPS3组件即可 , 如下图所示 。
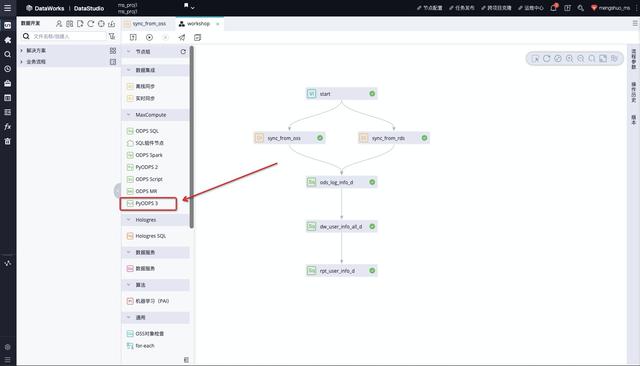 文章插图
文章插图【持续定义SaaS模式云数据仓库+AI】目前 , Mars已经可以试用 , SQLML马上就会和大家见面 , 欢迎大家进行试用 。
- 虾米音乐正式宣告关停:国内音乐平台终告别“三国杀”,TME一家独大或将持续
- 零售新物种苏宁趣逛逛,重新定义逛街
- "二八定律"难破 CPU市占率英特尔持续占优
- 科技周刊荐读 | AI重新定义未来建筑;江苏智造,诠释“科技原创”深刻内涵;“万物互联”的“智能社会”还有多远?
- OPPO设计款手机,重新定义折叠屏
- 功能|微软新专利曝光:计算机面板可同时定义外观与功能
- 终于可以自定义喇叭声:你的特斯拉可以“放屁”吓唬人了
- 连获两项科技创新成果,聚好看科技持续发力AI+5G
- 微软正在设想一种可更换的计算机面板 可同时定义外观与功能
- 清华大学研究院出手!擦一次,持续24小时防雾,改变眼镜党体验