快速概览 + 详细了解N:N聚类算法是如何应用的( 二 )
举个例子 , 假如说你有很多的语音片段(语音的文本内容是相同的) , 这些语音片段分别归属于甲乙丙丁等人;仅凭人耳辨识是无法分辨出哪些语音片段属于甲 , 哪些语音片段属于乙 。
通过N:N聚类的算法 , 进行声纹的相似度检测 , 将属于同一个人说话的语音片段不断进行合并归类;最后属于甲说话的语音片段全部被归为一类 , 属于乙说话的语音片段全部被归为一类;以此类推 , 类内语音的相似度极高 , 类间语音的相似度较低 , 达到将这些语音片段分人整理的目的 。
简单介绍一下聚类分析:聚类分析是根据在数据中发现的描述对象及其关系的信息 , 将数据对象分组 。
目的是——组内的对象相互之间是相似的(相关的) , 而不同组中的对象是不同的(不相关的);组内相似性越大 , 组间差距越大 , 说明聚类效果越好 。
聚类效果的好坏依赖于两个因素:
- 衡量距离的方法(distance measurement) ;
- 聚类算法(algorithm) 。
其基本思想是从每个语片段中提取特征参数 , 例如梅尔倒谱参数 , 计算每两个语音段之间特征参数的相似度 , 并利用BIC判断相似度最高的两个语音段是否合并为同一类 。
对任意两段语音都进行上述判决 , 直到所有的语音段不再合并 。
——摘自“说话人聚类的初始类生成方法”
聚类&声纹识别的主要场景:在跨渠道、跨场景收集语音同时建立声纹库的时候;由于各场景应用的客户账号或许不同 , 说话人在不同场景中分别注册过声纹 , 难以筛除重复注册语音 , 建立统一声纹库 。
我们如何快速的去筛除属于某一个人在不同情况下录制的多条录音文件?也就是如何保证最终留下的录音文件(声纹库)是唯一的?
每一个人只对应一条音频 , 这就要用到聚类的算法;利用声纹识别N:N说话人聚类 , 对所有收集到的语音进行语音相似度检测 , 将同一说话人在不同场景中的多次录制的语音筛选出来;并只保留其中一条 , 从而保证了声纹库的独特性 , 节省了大量的人力成本、资源成本 。
对于目前的场景 , 我们选择凝聚层次聚类算法 , 在这种场景下 , 我们是要筛除重复人说话;那么我们可以将每一个录音文件都当作一个独立的数据点 , 看最后有凝聚出多少个独立的数据簇 , 此时可以理解为类内都是同一个人在说话 。
1)我们首先将每个数据点(每一条录音文件)视为一个单一的类 , 即如果我们的数据集中有 X 个数据点 , 那么我们就有 X 个类;然后 , 我们选择一个测量两个类之间距离的距离度量标准;作为例子 , 我们将用 average linkage , 它将两个类之间的距离定义为第一个类中的数据点与第二个类中的数据点之间的平均距离(这个距离度量标准可以选择其他的) 。
2)在每次迭代中 , 我们将两个类合并成一个;这两个要合并的类应具有最小的 average linkage , 即根据我们选择的距离度量标准 , 这两个类之间的距离最小;因此是最相似的 , 应该合并在一起 。
3)重复步骤 2 直到我们到达树根 , 即我们只有一个包含所有数据点的类 。 这样我们只需要选择何时停止合并类 , 即何时停止构建树 , 来选择最终需要多少个类(摘自知乎) 。
按照实际的场景 , 如果我们最终要得到1000个不重复的录音文件 , 为了防止过度合并 , 定义的退出条件是最后想要得到的录音文件数目 。
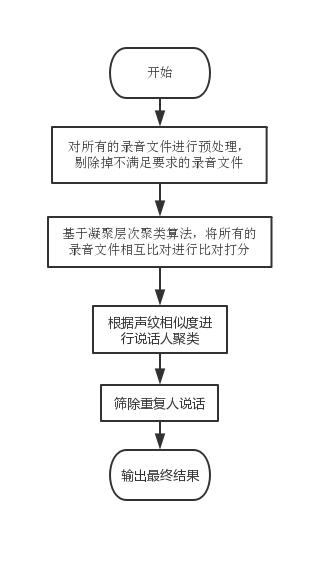 文章插图
文章插图处理的流程图
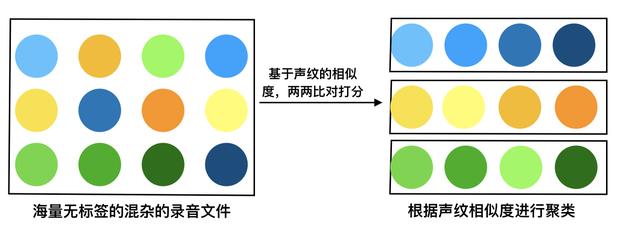 文章插图
文章插图
- “千店同开”引质量担忧,小米回应
- 企业|技术快速迭代倒逼知识产权“贴身”服务,上海首家AI商标品牌指导站入驻徐汇西岸
- 三星Galaxy A52 5G通过3C认证 支持最高15W快速充电
- 大健康速递丨腾讯上线疫苗接种服务区;华大基因研发出快速鉴定盒
- 小米联合京东及爱回收推全新换机服务 帮你快速换新机
- 西安奕斯伟硅产业基地项目建设刷新我国建设大硅片制造项目的最快速度
- 网络|万物互联,更离不开网络文明
- 微软统一Edge工具栏体验:方便用户快速访问收藏夹、历史和集锦
- AirPods Max是如何低功耗运作的,来看详细说明
- 超好用的UnixLinux 命令技巧 大神为你详细解读