大白话给你讲分布式架构,3分钟让你学一遍( 二 )
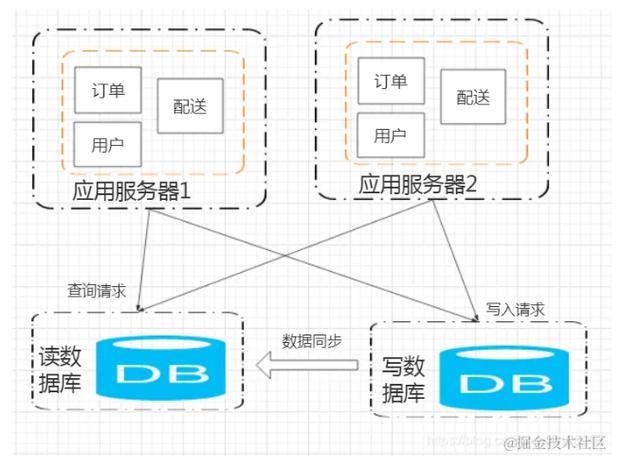
数据库读写分离应用层的问题暂时解决了 , 但是此时数据库又顶不住了 。 那该如何做呢?
只是简单的增加数据库的服务器来提供存储和访问能力么?那肯定不行 , 这样数据就不一致了 。
所以我们需要将数据库分为读库和写库 。 查询请求都到读库去 , 而写入请求都到写库去 。
 文章插图
文章插图
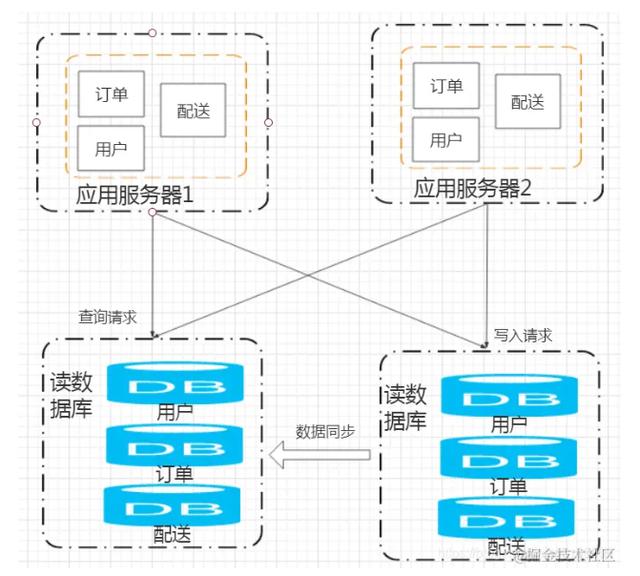
但这样也存在几个问题:
- 数据如何同步以及同步延迟如何处理?
- 应用层数据源的选择
- 大数据查询搜索 , 可以引入搜索引擎
- 避免每次访问直接到达数据库 , 可以引入redis等缓存数据库缓存热点数据
- 水平拆分:将同一个表中的数据拆分至多个数据库中
- 垂直拆分:将不同业务的数据放到不同的数据库中
 文章插图
文章插图应用拆分
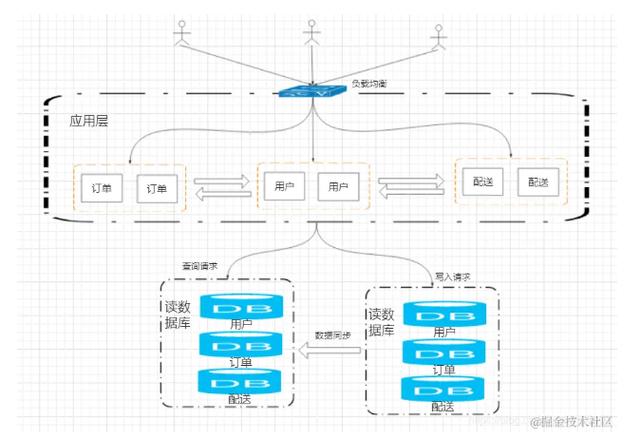
业务继续增长 , 数据库达到瓶颈时可以继续增加服务器解决 , 但是应用层呢?也只是单纯的增加服务器么?
基于二八原则 , 其实大部分访问量是集中在20%的功能上的 , 如果我们只是单纯的增加服务器 , 那么无疑会浪费掉许多的资源 , 所以我们会想到能不能针对这20%的应用做扩展呢?
当然是可以的 , 只不过我们需要先将应用拆分为多个子系统(一般是根据业务):
 文章插图
文章插图随着应用拆分随之而来的问题是 , 公用的代码如何处理?各服务之间如何通信?
公用代码我们不可能放到每个服务中去 , 而是应该提出来对外提供服务 , 同时服务之间的调用可以通过RPC或者HTTP方式来实现 。
演化至此 , 这样的架构就是一个成熟的分布式架构了 。
但是 , 架构还是会随着业务和技术的提升不停地演化;而此时你有没有发现这样的一个架构和冯诺伊曼结构很像呢!
输入输出设备对应用户和服务之间的输入输出 , 数据库服务器就像是存储设备 , 而整个应用层就像是一个CPU(控制器、运算器) 。
所以 , 分布式架构可以简单的理解为将多台计算机组成的一台超级计算机 。
三、分布式架构的设计在设计分布式架构时 , 我们需要了解几个基本的概念 。
- 主流架构模型-SOA和微服务
- CAP和BASE理论
- DDD(领域驱动设计)
分布式架构的高可用设计在分布式架构中 , 常常面临的两个矛盾的问题是一致性和高可用 , 这两个是无法同时满足的 , 那我们舍谁取谁呢?
从用户的角度分析 , 我们宁可获取到旧数据 , 也不愿意等半天都打不开应用 , 所以常常是保证高可用 , 让数据达到最终一致性 , 那么如何设计高可用的分布式架构呢?主要从以下几个方面:
- 搭建服务集群 , 提高负载 , 避免单点故障 。 尤其是特别重要的服务 , 如访问量较高的服务和核心服务(一旦挂掉就会导致整个应用不可用的服务) 。
- 应对灾难 , 搭建异地灾备 , 预防地区因发生地震、台风等自然灾害导致地区的集群服务器都不可用 。
- 接口限流以及服务降级 。 为防止过高的并发量造成服务器负载过高而出现故障 , 应对接口限流 , 同时 , 当某个或多个服务出现故障时 , 应当服务降级 , 避免拖累整个应用 。 比如支付时因网络故障等导致无法支付 , 但搜索商品和下单仍然可用 。
- 轻盈机身打造唯美手感,vivo Y73s给你全新5G体验
- java 从零实现属于你的 redis 分布式锁
- 暖手+化妆+充电的臻美暖手宝,这个冬天,颐和园给你温暖专宠丨种草机
- 女子花7780元买的手机,却出现绿屏,商家:再加二百元给你退
- HarmonyOS 2.0手机开发者Beta版真来了!快来升级EMUI11提前感受分布式技术
- 四核强性能,华硕XD4灵耀AX魔方分布式路由评测
- 不同微单系统对焦有何区别?这篇文章给你答案
- 为升级鸿蒙做准备 EMU 11分布式技术提前预演
- 分布式天花板?阿里百万架构师的ZK+Dubbo笔记,颠覆认知
- realme真我Q2评测:千元敢越级给你想要的5G体验