比甜品卡更甜!映众RTX 3060 Ti 冰龙超级版评测( 二 )
 文章插图
文章插图
映众RTX 3060 Ti 冰龙超级版
映众GeForce RTX 3060 Ti冰龙超级版显卡基于NVIDIA公版方案 , 配备了6+2相供电 , 电源部分显卡采用8Pin接口设计, 使用上一代显卡的玩家可以轻松过渡 , 使用600W以上电源的玩家无需更换电源即可实现拔插升级 。
 文章插图
文章插图
映众RTX 3060 Ti 冰龙超级版
在视频输出接口上 , 映众GeForce RTX 3060 Ti冰龙超级版显卡采用DP*3+HDMI 2.1的4接口设计 , 充分满足用户的扩展需求;另外由于本次HDMI 2.1的升级 , 该接口可支持单线8K的视频输出;同时接口上还采用了镀金设计 , 不易被氧化 , 有效延长接口的寿命 。
 文章插图
文章插图
映众RTX 3060 Ti 冰龙超级版
02NVIDIA Ampere架构下RTX 3060 Ti
映众RTX 3060 Ti 冰龙超级版采用了NVIDIA Ampere架构 , 我们首先来看一下RTX 3060 Ti的提升 。
 文章插图
文章插图
第一代RTX架构 Turing下的RTX 2060 SUPER
 文章插图
文章插图
第二代RTX架构 Ampere下的RTX 3060 Ti
相较于初代的Turing RTX架构 , NVIDIAAmpere架构在算力上有着成倍的增长 , 这一点在RTX 3060 Ti中依旧有体现 , 每个时钟执行2次着色器运算 , 而Turing为1次 , RTX 3060 Ti的着色器性能达到16.2 TFLOPS单精度性能 , 而Turing为7.2 TFLOPS 。
NVIDIAAmpere架构翻倍了光线与三角形的相交吞吐量 , RT Core达到31.6 RTTFLOPS , 而Turing为21.7 RT TFLOPS 。
全新的Tensor Core可自动识别并消除不太重要的DNN权重 , 处理稀疏网络的速率是Turing的两倍 , 算力高达129.6 TensorTFLOPS , 而Turing为57.4 TensorTFLOPS 。
 文章插图
文章插图
RTX 3060 Ti采用GA104核心拥有174亿个晶体管 , 392平方毫米的面积 , 基于三星的8nm NVIDIA定制工艺 , 另外在RTX 3060 Ti中我们都知道仍然采用了GDDR6显存 , 不过不同于RTX 3080的Micron , RTX 3060 Ti采用了三星的GDDR6显存 。
我们在发布会中经常听到性能翻倍的说法 , 其实是因为本次NVIDIAAmpere的SM在Turing基础上增加了一倍的FP32运算单元 , 这就使得每个SM的FP32运算单元数量提高了一倍 , 同时吞吐量也就变为了一倍 。
而通常我们计算显卡的CUDA数量 , 并不是把SM中的所有单元加起来计数 , 而是只统计FP32单元的数量 , 所以这样一来 , SM中的【FP32 : INT32】 从 1:1 变为 2:1 。
RTX 3060 Ti共有4864个CUDA , 其实它有2432个INT32单元 , 但由于内部的FP32数量翻了一倍 , 所以最终实现了4864这个惊人的数字 。
而这样粗暴的提升CUDA数量对于游戏其实有着非常大的帮助 , 通常在游戏中浮点运算相比整数计算要常用的多 , 图形、算法以及各种计算操作中着色器工作负载通常需要混合使用FP32算数指令 , 而FP32的加速也有助于光线追踪降噪着色器 。
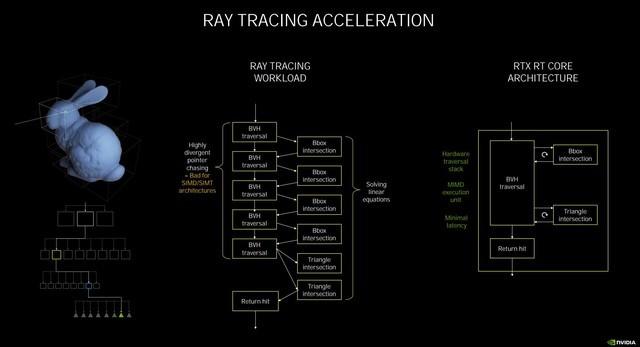 文章插图
文章插图
光追工作原理示意
在此次的NVIDIAAmpere架构中 , NVIDIA官方宣布为第二代RT Core , 它和第一代有什么不同呢 。 首先要知道RT Core的工作原理是 , 着色器发出光线追踪的请求 , 交给RT Core来处理 , 它将进行两种测试 , 分别为边界交叉测试(Box Intersection testing)和三角形交叉测试(Triangle Intersectiontesting) 。 基于BVH算法来判断 , 如果是方形 , 那么就返回缩小范围继续测试 , 如果是三角形 , 则反馈结果进行渲染 。
- 畅爽2077 耕升RTX 3060Ti 星极甜品新选择
- 三头六臂钛强悍 映众RTX3060TI显卡首发
- 光追甜品俯视上代次旗舰 技嘉GEFORCE RTX 3060Ti魔鹰PRO首发评测
- 映众RTX3090冰龙超级版评测:强劲散热安心超频
- 主流价位甜品游戏本新选择,宏碁掠夺者战斧300评测
- 现象级显卡再度降临,第二代光追甜品666!索泰 GeForce RTX 3060Ti-8GD6天启 OC首发评测