PPDet:减少Anchor-free目标检测中的标签噪声,小目标检测提升明显( 三 )
与其他anchor-free方法相似 , 在本文的模型中 , 会对分配给目标对象的每个前景特征进行训练以预测其目标的GT框的坐标 。
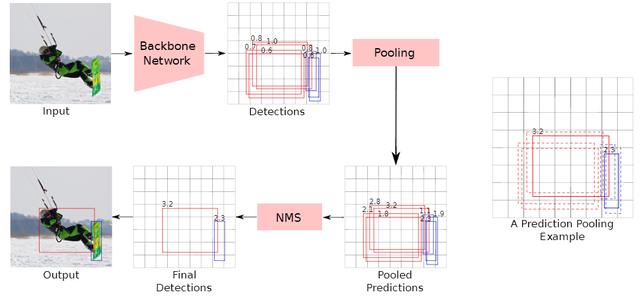
2、 Inference推理PPDet的推理流程如图3所示 。 首先 , 将输入图像送入到产生初始检测集的主干神经网络模型 。
每次检测都与(i)边界框、(ii)目标类别(选择为具有最大概率的类)和(iii)置信度得分相关联 。
在这些检测中 , 将消除使用背景类标记的检测 , 并将在此阶段剩余的每个检测都视为对其所属目标类别的投票 , 其中方框是目标位置的假设 , 置信度得分是投票的强度 。 如果属于同一目标类别的两个检测重叠超过一定量(即交并比(IoU)> 0.6) , 则将它们视为对同一目标的投票 , 并且每个检测的得分相比于其他检测的分数增加k的(IoU-1.0)次方倍 , 其中K为常数 。
因此 , IoU越多 , 增加幅度越大 。 将这一过程应用于每对检测后 , 将获得最终检测的分数 。 此步骤之后是NMS操作 , 该操作会产生最终检测结果 。
 文章插图
文章插图
图3 :(左)PPDet推理流程的示意图 。 预测的人和滑雪板框分别以红色和蓝色显示 。 红色和蓝色方框相互投票 。 (右)一个pooling示例 。 虚线边界红框投给实线红框 , 虚线边界蓝框投给实线蓝框 。 图中显示的是实心框的最终得分(汇总后) 。
值得注意的是 , 尽管推理中使用的预测池似乎与训练中使用的池不同 , 但实际上 , 它们是相同的过程 。 训练中使用的假设是由正区域中的特征预测的边界框彼此完全重叠(即IoU = 1) , 可以看作推理过程的一个特例 。
3、 网络框架
PPDet使用RetinaNet的网络模型作为整体框架 , 它由一个主干卷积神经网络(CNN)和一个特征金字塔网络(FPN)组成 。 FPN计算多尺度的特征表示 , 并产生五个不同尺度的特征图 。
在每个FPN层的顶部有两个独立的并行网络 , 即分类网络和回归网络 。 分类网络输出一个W×H×C的张量 , 其中W和H是空间维度(分别是宽度和高度) , C是类别数量 。 同样 , 回归网络输出一个W×H×4的张量 , 其中4是边界框坐标的数量 , 并将这些张量中的每个像素称为一个特征 。
3 实验与结果
数据集:COCO
消融实验:
1、Size of the “positive area”
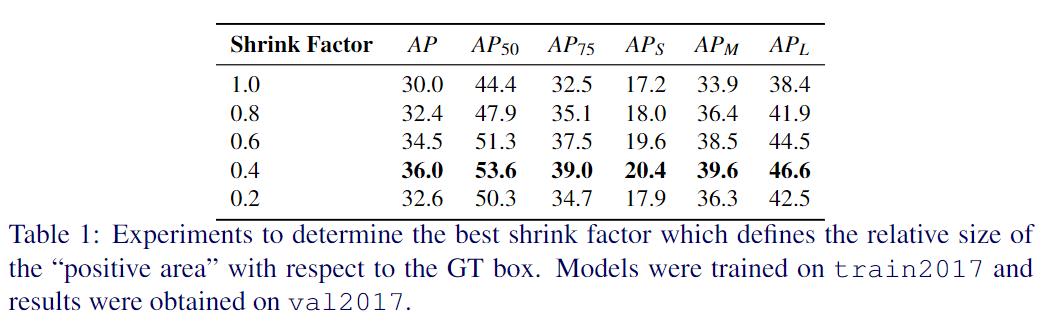
如前所述 , 将“正区域”定义为与GT框同心且形状与GT框相同的区域 。 实验中通过将“正区域”的宽度和高度乘以收缩因子来调整其大小 。 用收缩系数在1.0和0.2之间进行了实验 。
表1中显示了性能结果 。 但是 , 从缩小系数1.0到0.4 , mAP会增加 , 但是在那之后性能会急剧下降 。 基于这种消融 , 将其余的实验的收缩因子设置为0.4 。
 文章插图
文章插图
2、Regression loss weight
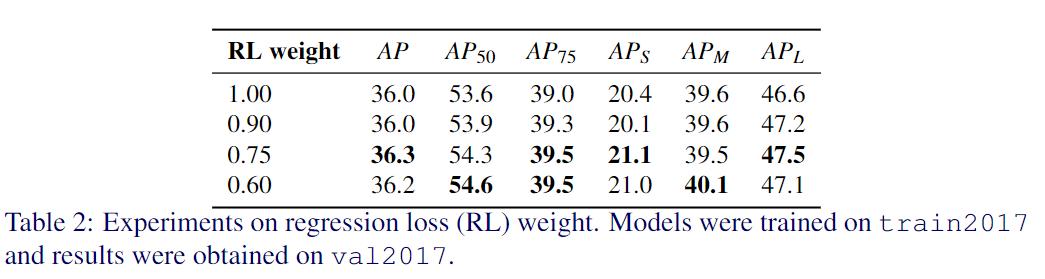
为了找到分类和回归损失之间的最佳平衡 , 对回归损失权重进行了消融实验 。 如表2所示 , 最好的结果是0.75 。 在其余的实验中 , 也将回归损失的权重设置为0.75 。
 文章插图
文章插图
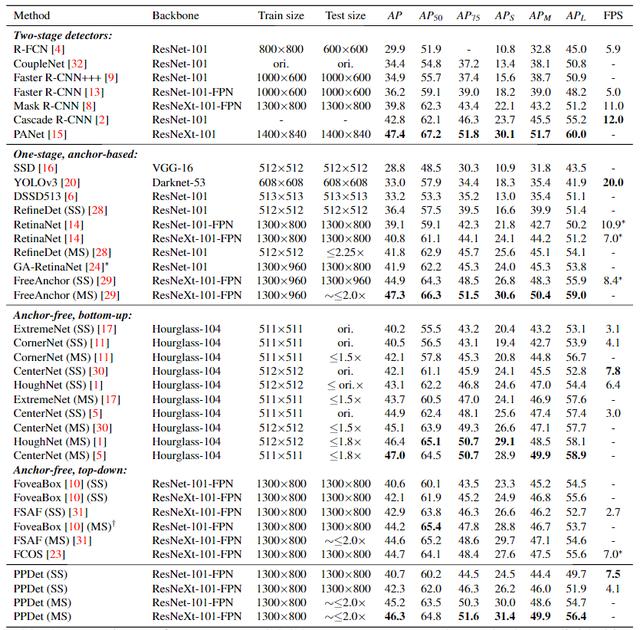
对比实验
 文章插图
文章插图
更多细节可参考论文原文 。
 文章插图
文章插图
- 减少八成二次包装 绿色快递年底可期
- 嗅觉AI:为减少食物浪费出点力
- 网站改版时如何减少网站的损失?
- 不顾240亿经济损失!意大利做出意外决定:将减少采购华为设备
- 手机充电“一整夜”,会不会减少电池寿命?维修老师傅这样回答
- 或与美国劝说有关?传意大利电信意外决定:计划减少华为设备份额
- 手机信号栏出现"HD",别不当回事儿,你的话费可能已经在减少
- 脑洞大开!印度推出牛粪“芯片”:声称能减少手机辐射预防疾病
- 麻烦一大堆!部分地区运营商下架4G套餐 种类减少办理渠道也在变窄
- 手机信号栏冒出“HD”,别不当回事儿,你的话费可能已经在减少