TensorFlow| PWIL:不依赖对抗性的新型模拟学习
 文章插图
文章插图
文 / 研究软件工程师 Robert Dadashi 和 学生研究员 Léonard Hussenot , Google Research
强化学习 (Reinforcement Learning , RL) 是一种通过反复试验训练智能体 (Agent) 在复杂环境中有序决策的范式 , 在游戏、机器人操作和芯片设计等众多领域都取得了巨大成功 。 智能体的目标通常是最大化在环境中收集的总奖励 (Reward) , 这可以基于速度、好奇心、美学等各种参数 。 然而 , 由于 RL 奖励函数难以指定或过于稀疏 , 想要设计具体的 RL 奖励函数并非易事 。
游戏这种情况下 , 模仿学习 (Imitation Learning , IL) 方法便派上了用场 , 因为这种方法通过专家演示而不是精心设计的奖励函数来学习如何完成任务 。 然而 , 最前沿 (SOTA) 的 IL 方法均依赖于对抗训练 , 这种训练使用最小化/最大化优化过程 , 但在算法上不稳定并且难以部署 。
在“原始 Wasserstein 模仿学习”(Primal Wasserstein Imitation Learning , PWIL) 中 , 我们基于 Wasserstein 距离(也称为推土机距离)的原始形式引入了一种新的 IL 方法 , 这种方法不依赖对抗训练 。 借助 MuJoCo 任务套件 , 我们通过有限数量的演示(甚至是单个示例)以及与环境的有限交互来模仿模拟专家 , 以此证明 PWIL 方法的有效性 。
原始 Wasserstein 模仿学习MuJoCo 任务套件#mujoco 文章插图
文章插图
左图:使用任务的真实奖励(与速度有关)训练的算法类人机器人“专家”;右图:使用 PWIL 基于专家演示训练的智能体
对抗模仿学习
最前沿的对抗 IL 方法的运作方式与生成对抗网络 (GAN) 类似:训练生成器(策略)以最大化判别器(奖励)的混淆度 , 以便判别器本身被训练来区分智能体的状态-动作对和专家的状态-动作对 。 对抗 IL 方法可以归结为分布匹配问题 , 即最小化度量空间中概率分布之间距离的问题 。 不过 , 就像 GAN 一样 , 对抗 IL 方法也依赖于最小化/最大化优化问题 , 因此在训练稳定性方面面临诸多挑战 。
训练稳定性方面面临诸多挑战模仿学习归结为分步匹配
PWIL 方法的原理是将 IL 表示为分布匹配问题(在本例中为 Wasserstein 距离) 。 第一步为从演示中推断出专家的状态-动作分布:即专家采取的动作与相应环境状态之间的关系的集合 。 接下来的目标是通过与环境的交互来最大程度地减少智能体的状态-动作分布与专家的状态-动作分布之间的距离 。 相比之下 , PWIL 是一种非对抗方法 , 因此可绕过最小化/最大化优化问题 , 直接最小化智能体的状态-动作对分布与专家的状态-动作对分布之间的 Wasserstein 距离 。
PWIL 方法
计算精确的 Wasserstein 距离会受到限制(智能体轨迹结束时才能计算出) , 这意味着只有在智能体与环境交互完成后才能计算奖励 。 为了规避这种限制 , 我们为距离设置了上限 , 可以据此定义使用 RL 优化的奖励 。
结果表明 , 通过这种方式 , 我们确实可以还原专家的行为 , 并在 MuJoCo 模拟器的许多运动任务中最小化智能体与专家之间的 Wasserstein 距离 。 对抗 IL 方法使用来自神经网络的奖励函数 , 因此 , 当智能体与环境交互时 , 必须不断对函数进行优化和重新估计 , 而 PWIL 根据专家演示离线定义一个不变的奖励函数 , 并且它所需的超参数量远远低于基于对抗的 IL 方法 。
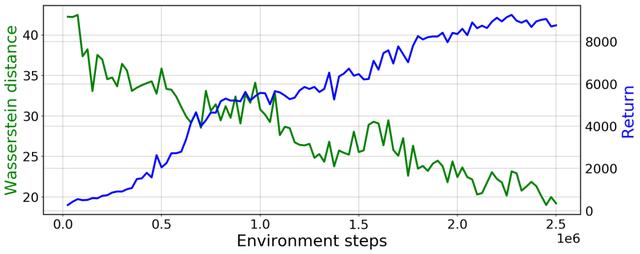 文章插图
文章插图
PWIL 在类人机器人上的训练曲线:绿色表示与专家状态-动作分布的 Wasserstein 距离;蓝色表示智能体的回报(所收集奖励的总和)
- 印度这是在玩火?与日本联手合作5G技术,只为摆脱中国技术依赖
- 轻巧无依赖,Javascript简单的轮播插件——Siema
- Python|TensorFlow 、Caffe等9大主流人工智能框架优劣势分析
- 65亿元购下英特尔专利,苹果开始自研基带芯片,或不再依赖高通
- 国内已具备批量生产高端剃须刀用钢能力,酒钢再次打破依赖进口
- 为什么分布式应用程序需要依赖管理?
- 对比PyTorch和TensorFlow的自动差异和动态模型
- 5个简单的步骤掌握Tensorflow的Tensor
- 库克回应用户沉溺设备 称不会设计让人过分依赖的产品
- 使用tensorflow和Keras的初级教程