爱可可AI论文推介(10月13日)( 三 )
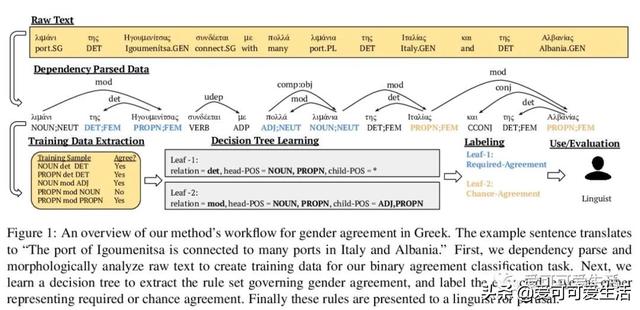
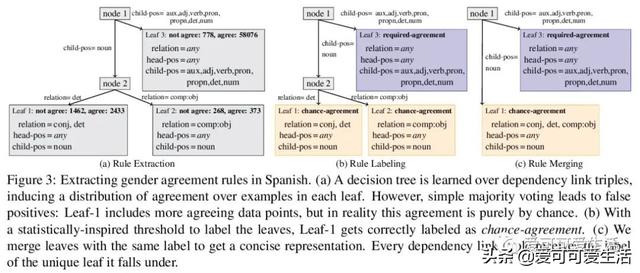
Creating a descriptive grammar of a language is an indispensable step for language documentation and preservation. However, at the same time it is a tedious, time-consuming task. In this paper, we take steps towards automating this process by devising an automated framework for extracting a first-pass grammatical specification from raw text in a concise, human- and machine-readable format. We focus on extracting rules describing agreement, a morphosyntactic phenomenon at the core of the grammars of many of the world's languages. We apply our framework to all languages included in the Universal Dependencies project, with promising results. Using cross-lingual transfer, even with no expert annotations in the language of interest, our framework extracts a grammatical specification which is nearly equivalent to those created with large amounts of gold-standard annotated data. We confirm this finding with human expert evaluations of the rules that our framework produces, which have an average accuracy of 78%. We release an interface demonstrating the extracted rules at this https URL.
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
5、[CV]Image GANs meet Differentiable Rendering for Inverse Graphics and Interpretable 3D Neural Rendering
(Under review as a conference paper at ICLR 2021)
将生成模型与可微渲染结合提取并解缠生成式图像合成模型学到的三维知识 , 利用GAN作为多视图数据生成器 , 用可微渲染器训练逆图形网络 , 将训练好的逆图形网络作为教师 , 将GAN潜代码解缠为可解释的3D属性 , 用循环一致性损失迭代训练整个网络结构 。 可获得显著高质量的三维重建结果 , 而需要的注释工作比标准数据集少10000次 。
Differentiable rendering has paved the way to training neural networks to perform “inverse graphics” tasks such as predicting 3D geometry from monocular photographs. To train high performing models, most of the current approaches rely on multi-view imagery which are not readily available in practice. Recent Generative Adversarial Networks (GANs) that synthesize images, in contrast, seem to acquire 3D knowledge implicitly during training: object viewpoints can be manipulated by simply manipulating the latent codes. However, these latent codes often lack further physical interpretation and thus GANs cannot easily be inverted to perform explicit 3D reasoning. In this paper, we aim to extract and disentangle 3D knowledge learned by generative models by utilizing differentiable renderers. Key to our approach is to exploit GANs as a multi-view data generator to train an inverse graphics network using an off-the-shelf differentiable renderer, and the trained inverse graphics network as a teacher to disentangle the GAN's latent code into interpretable 3D properties. The entire architecture is trained iteratively using cycle consistency losses. We show that our approach significantly outperforms state-of-the-art inverse graphics networks trained on existing datasets, both quantitatively and via user studies. We further showcase the disentangled GAN as a controllable 3D “neural renderer", complementing traditional graphics renderers.
- 谷歌:想发AI论文?请保证写的是正能量
- 谷歌对内部论文进行“敏感问题”审查!讲坏话的不许发
- 2019年度中国高质量国际科技论文数排名世界第二
- 谷歌通过启动敏感话题审查来加强对旗下科学家论文的控制
- Arxiv网络科学论文摘要11篇(2020-10-12)
- 聚焦城市治理新方向,5G+智慧城市推介会在长举行
- 中国移动5G新型智慧城市全国推介会在长沙举行
- 年年都考的数字鸿沟有了新进展?彭波老师的论文给出了解答!
- 打开深度学习黑箱,牛津大学博士小姐姐分享134页毕业论文
- 爱可可AI论文推介(10月9日)