科普丨一文深入了解IPFS( 三 )
IPFS命令行工具可以无缝地跟随目录链接名称来遍历文件系统:
版本文件系统
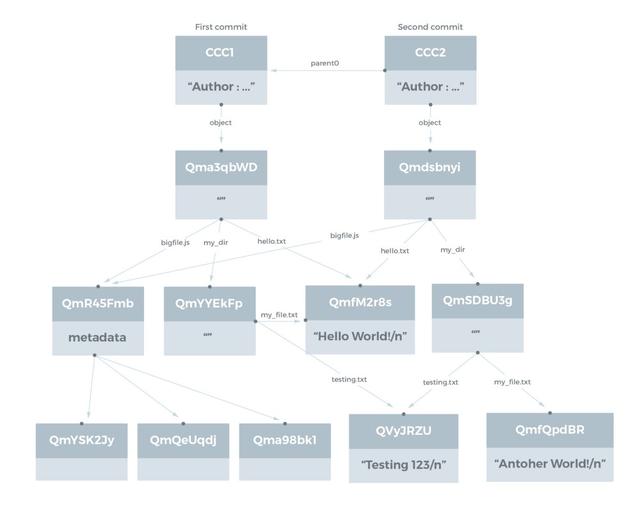
IPFS可以代表Git用于版本化文件系统的数据结构 。 Git提交对象在Git Book中进行了描述 。 在撰写本文时 , 尚未完全指定IPFS提交对象的结构 , 讨论仍在进行中 。
提交对象的主要属性是它具有一个或多个链接 , 其名称为parent0 , parent1等 , 指向先前的提交 , 并且具有名称对象的链接(在Git中称为tree) , 该链接指向该对象引用的文件系统结构 。
我们以前面的文件系统目录结构以及两次提交为例:第一次提交是原来的结构 , 并在第二次提交 , 我们已经更新了文件my_file.txt , 表示另一个世界 , 而不是原始的“Hello World!” 。
 文章插图
文章插图
这里还要注意 , 我们具有自动重复数据删除功能 , 因此第二个提交中的新对象只是主目录 , 新目录my_dir和更新后的文件my_file.txt 。
03 区块链
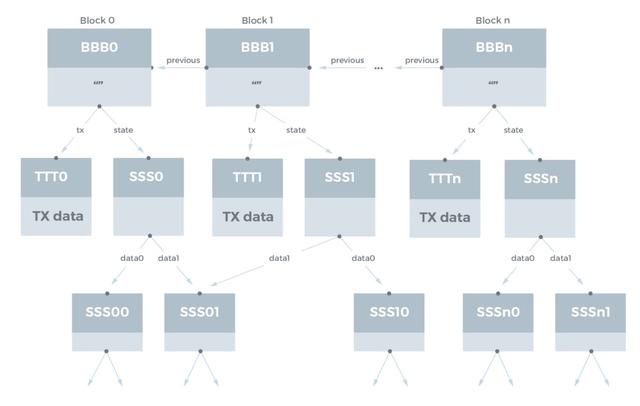
这是IPFS最令人兴奋的用例之一 。 区块链具有自然的DAG结构 , 因为过去的区块始终通过其后继区块的哈希值进行链接 。 以太坊区块链等更高级的区块链也有一个关联的状态数据库 , 该数据库具有Merkle-Patricia树结构 , 也可以使用IPFS对象进行仿真 。
我们假设一个简单的区块链模型 , 其中每个块包含以下数据:
交易对象列表;
到上一个块的链接;
状态树/数据库的哈希 。
然后可以在IPFS中按以下方式对该区块链进行建模:
 文章插图
文章插图
当将状态数据库放在IPFS上时 , 我们看到了重复数据删除的好处——在两个块之间 , 只有已更改的状态项需要显式存储 。
这里有趣的一点是 , 将数据存储在区块链上与将数据哈希存储在区块链上之间的区别 。 在以太坊平台上 , 您需要支付相当大的费用才能将数据存储在关联的状态数据库中 , 以最大程度地减少状态数据库的膨胀(区块链膨胀) 。 因此 , 这是一种常见的设计模式 , 即较大的数据不存储数据本身 , 而是存储状态数据库中数据的IPFS哈希 。
如果在IPFS中已经表示了具有相关状态数据库的区块链 , 那么将哈希存储在区块链上和将数据存储在区块链上的区别就变得有些模糊了 , 因为无论如何所有内容都存储在IPFS中 , 并且只需要区块的哈希即可状态数据库的哈希 。 在这种情况下 , 如果有人在区块链中存储了IPFS链接 , 我们可以无缝地跟随该链接来访问数据 , 就像数据存储在区块链本身中一样 。
但是 , 我们仍然可以区分链上和链下数据存储 。 我们通过查看矿工在创建新区块时需要处理的内容来做到这一点 。 在当前的以太坊网络中 , 矿工需要处理将更新状态数据库的交易 , 为此 , 他们需要访问完整状态数据库 , 以便能够在更改后的任何地方对其进行更新 。
因此 , 在以IPFS表示的区块链状态数据库中 , 我们仍然需要将数据标记为“链上”或“链下” 。 对于矿工来说 , “链上”数据对于本地挖矿是必不可少的 , 并且该数据将直接受到交易的影响 。 “链下”数据将必须由用户更新 , 而矿工则无需接触 。
作者:鸵鸟区块链;来自链得得内容开放平台“得得号” , 本文仅代表作者观点 , 不代表链得得官方立场凡“得得号”文章 , 原创性和内容的真实性由投稿人保证 , 如果稿件因抄袭、作假等行为导致的法律后果 , 由投稿人本人负责得得号平台发布文章 , 如有侵权、违规及其他不当言论内容 , 请广大读者监督 , 一经证实 , 平台会立即下线 。 如遇文章内容问题 , 请发送至邮箱:linggeqi@chaindd.com
- 全新8核国产CPU深入探秘:马上能买到
- 高通换帅!现任CEO莫伦科普夫将于年中退休 阿蒙继任
- 从工程师到“水果猎人”他在百度做科普
- 一文读懂,书架箱和落地箱到底哪个好?
- 有史以来最大升级?一文看懂OriginOS带来的改变
- 16G运存+256G内存,专业骁龙865旗舰,性价比深入人心
- 超大杯来了!一文看懂OPPO Reno5 Pro+最大升级
- 深入理解Netty编解码、粘包拆包、心跳机制
- 中国电信科普:换手机后这五件事一定要做
- 简单一文教你制作多语言的Qlik Sense应用程序